記者張筱涵/綜合報導
中信兄弟啦啦隊人氣成員峮峮,對於中信兄弟外野手陳子豪確定離隊,以破億合約加盟味全龍,特地在社群平台發文送上祝福,展現出深厚的情誼與支持。
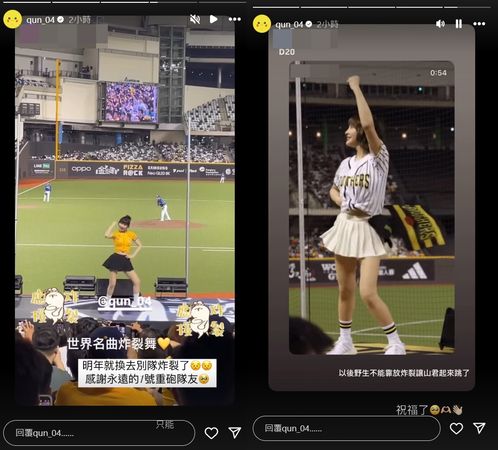
峮峮今(20日)在Instagram限時動態中轉發粉絲上傳的「世界名曲《炸裂陳子豪》舞蹈」影片,並寫道:「明年就換去別隊炸裂了,感謝永遠的1號重砲隊友。」她在限動最下方黑底區域悄悄寫下「只能」,隨後轉發另一位網友的影片補充「祝福了」。兩段文字均配上淚眼汪汪和比愛心的表情符號,流露出不捨之情,也為隊友的未來送上最真摯的祝福。
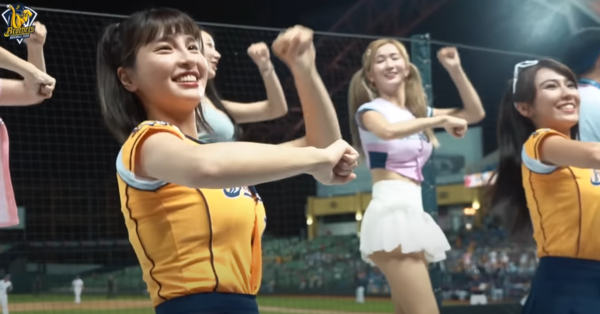
隨著陳子豪披上味全龍的戰袍,應援曲《炸裂陳子豪》是否會隨著轉隊延續,仍是未知數。而峮峮在球場上為此曲帶動的經典舞步,恐怕也將成為絕響。
29歲的陳子豪本季出賽87場,繳出17發全壘打、60分打點的亮眼成績,打擊率達0.276。季後行使自由球員資格後,吸引多隊競逐,最終以5+5年的長期合約加盟味全龍。
陳子豪自2013年加入中信兄弟前身兄弟象隊,10年間成為球隊的靈魂人物之一。他的個人應援曲〈炸裂陳子豪〉,在峮峮活力四射的舞蹈帶動下,不僅成為球場經典,甚至紅遍全台,連不看棒球的大眾都對此耳熟能詳。

標題:陳子豪轉味全龍! 峮峮淚眼再見「炸裂舞」吐不捨心聲
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。