核心觀點
本篇報告的基本邏輯是,預期2025年外需將下降,就應該擴內需。內需包括投資和消費,但投資不是最終需求,投資可以形成資本,增加新的供給或新的產能;我國過去很長時間裏都側重於投資,尤其在基建投資和房地產投資方面更加明顯,故當前經濟面臨的主要壓力的供給過剩,需求不足,尤其是最終需求不足,即消費增速下行,故應該大力提振消費,聚焦最終需求,而不會像過去那樣側重於投資,盡管對於GDP增長目標的完成而言,投資可以起到立竿見影的“關鍵作用”。同時,當前經濟面臨的壓力不僅來自周期的波動,還來自改革开放以來經濟高增長過程中逐步累積起來的結構性壓力。因此,對於提振消費的難點要高度重視。
2025年,特朗普將就任美國第47任總統,他將推行重商主義政策,對包括中國在內的諸多國家加徵進口關稅,這無疑將影響我國的外需。中央經濟工作會議指出,當前外部環境變化帶來的不利影響加深。出口是近年中國經濟增長的重要動能,但2025年將面臨挑战。除了已討論較多的美國加徵關稅外,我們認爲也需要關注中國和新興市場國家關稅升級的可能。出口轉弱,會向制造業投資和消費等內需傳導,進而影響國內供求格局和物價形勢。
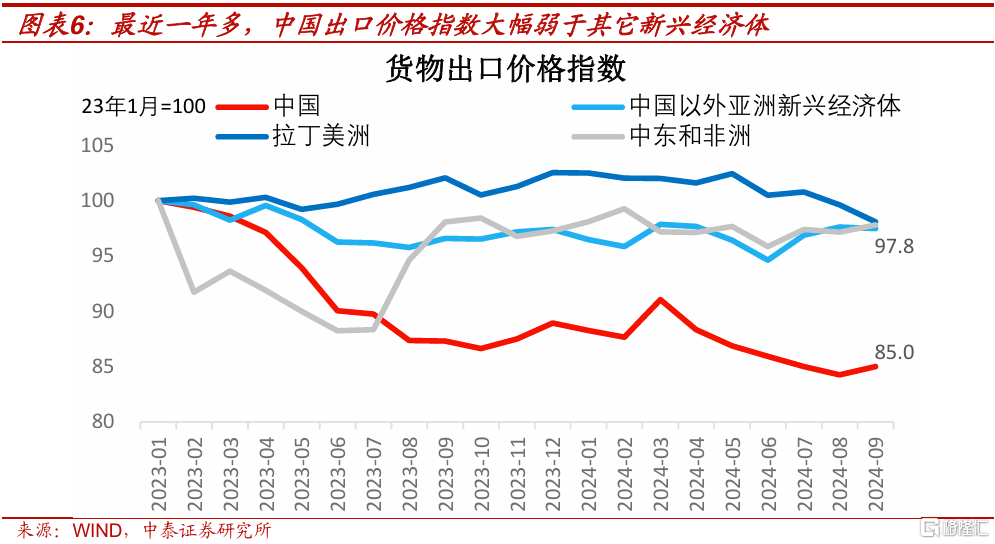
出口方面,2024年中國出口表現亮眼,但它主要源於“以價換量”。展望2025年,這種依托價格優勢帶來的出口高增長,或將面臨壓力。 測算顯示,美國對華產品加徵關稅,即使全部加徵到60%,對於美國CPI同比的影響可能也不到0.3個百分點。從對美國通脹的影響程度看,預計兩國達成共識存在難度。過去幾年中國出口增量主要來自於新興市場國家,中國和新興市場國家的產業結構具有相似性,既有合作也有競爭關系。 2023年年初到2024年9月,以美元計價的中國出口價格指數下跌15%,而同期其他主要新興市場的出口價格指數下跌在3% 以內。這種低價搶出口策略,可能令中國和新興市場國家產生利益衝突,不排除一些新興市場國家,2025年爲了保護本國產業,對中國部分產品加徵關稅的可能,這將讓中國的出口環境進一步惡化。
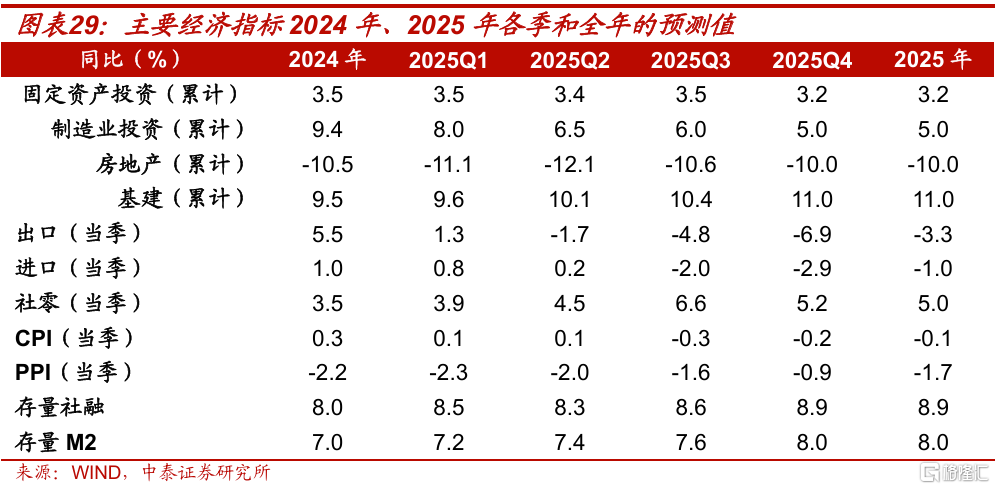
2025年中國制造業投資增速可能下降。 展望2025年,中國制造業部分子行業產能供過於求的局面或將持續。 供給端看,一是過去幾年制造業投資高增長,所形成的產能將逐步釋放;二是對比中國走出1998-2002年物價低迷的經驗看,當前供給端可能難以通過大規模破產來實現出清。 需求端看,外需走弱會直接抑制出口高依賴度行業的制造業投資。 2020年1月到2024年11月,出口高依賴度的12個制造業子行業, 投資累計增長62.3%,而非高出口依賴度的其他制造業子行業,同期投資增長了42.4%。 2025年高端制造業投資有望獲得信貸、財稅和產業等政策的支持,不過這些政策可能難以對衝企業自發性的資本开支意愿下降,預計制造業全年投資同比,將從2024年的9.4%左右,下降到2025年的5.0%左右。
2025年中國房地產銷售面積同比跌幅有望收窄,從-15%左右回升到-5.0% ,但房地產开發投資同比可能仍在-10.0%左右。 2025年房地產銷售面臨的壓力,一是中國居民部門實際償債壓力高於主要發達經濟體,外需走弱後,可能會通過就業、收入和預期的渠道,抑制居民購房意愿; 二是保交樓進展,會影響居民購买新房的積極性,建議關注專項債收儲土地和收購存量商品房政策的效果; 三是2016年-2024年中國住宅銷售, 預計將合計透支6.1億平方米,這從供給和需求兩端,增加了商品房銷售回暖的難度。 房地產投資方面,過去幾年新开工面積持續下降,會向2025年的施工面積傳導,樂觀假設下新开工面積同比從2024年的-23%回升到-15%,2025年施工面積同比跌幅和2024年的接近, 在-10%左右,房地產投資預計會繼續明顯拖累經濟。
2025年經濟結構再調整,公共消費與基建將是亮點。 2024年中央經濟工作會議,將全方位擴大國內需求,作爲2025年各項工作的首位。提振消費方面,我們測算顯示,若中國公共消費率回到全球平均水平,中國公共消費每年還有1萬億的增量空間。
我國最終消費對GDP的貢獻長期偏低,核心原因是居民可支配收入總額佔GDP的比重偏低,同時,作爲消費主體的中低收入群體與高收入群體之間存在相對固化的收入差距,也對消費提振帶來了難度,故推進收入分配制度的改革十分關鍵。
預計2025年提振消費的政策,一是加大以舊換新政策的力度,二是適當加大對特定困難群體的轉移支付,三是加大財政資金對教育、社保等公共服務領域的投入。預期2025年社會消費品零售總額的增速能達到5%左右。
擴大投資方面,從投資回報率的角度看,當前應該壓縮基建投資。但從對衝出口和地產走弱、托底經濟的角度看,2025年對基建投資依然有較高依賴,預計全口徑基建投資同比,將從2024年的9%左右,回升到11%左右。
2025年物價低位運行趨勢預計將持續。低基數下,預計全年PPI同比將從2024年的-2.2% ,回升到-1.7%;全年CPI同比,將從2024年的0.3% ,下降到-0.1%。
2024年中央經濟工作會議,定調“實施更加積極的財政政策和適度寬松的貨幣政策” ,也把保持就業總體穩定列爲2025年宏觀調控的目標之一,相關政策值得期待。財政政策方面,預計2025年廣義財政赤字將有3萬億左右的增量,即提高到12萬億左右,對應的廣義赤字率從7%左右提高到9%左右。
貨幣政策方面有四個判斷,一是人民幣匯率的波動彈性將加大;二是5%存款准備金率這一隱性下限或將放松,預計2025年全年降准幅度將達到或超過100bp;三是預計2025年7天期逆回購利率將下調50-60bp;四是預計2025年社融增速和M2增速將回升。
多措並舉穩定就業,也是2025年的重要工作。中央經濟工作會議做了相關部署,預計吸納就業尤其是年輕人就業多的服務業,有望得到政策傾斜。
風險提示:1、海外地緣政治衝突升級; 2、外部環境惡化導致中國出口超預期走弱; 3、國內政策力度和效果不及預期; 4、第三方數據失真的風險。
2025年特朗普將就任第美國總統,他將推行重商主義政策,對包括中國在內的諸多國家加徵進口關稅,這無疑將影響我國的外需。同時,他將推行的限制移民政策,又會推升勞動力價格,如果2025年再下調企業所得稅,使得美國的通脹預期進一步擡升。美聯儲降息周期或在2025年上半年結束,這無論對我國的增加出口還是我國實現適度寬松的貨幣政策等都將是一個考驗。
出口是2024年中國經濟增長的重要動能,2025年除美國加徵關稅外,也需要關注來自於新興經濟體貿易摩擦升級的可能。出口轉弱,又會向制造業投資和消費傳導,也會影響國內的供需格局和物價。中央經濟工作會議將全方位擴大國內需求放在2025年各項重點任務的首位,促消費和擴投資的增量政策都值得期待。
出口:2025年或將面臨較大挑战
2024年中國出口表現亮眼。2024年前11個月,美元和人民幣計價的名義出口同比分別爲5.4%、6.7%,剔除掉價格拖累後,兩種貨幣計價的中國實際出口同比分別達到了11.4%和12.2%。跟過去10年相比,2024年實際出口的表現,僅次於2021年。2024年前三季度,貨物和服務淨出口拉動GDP同比增長1.14個百分點,對經濟增長的貢獻率達到了23.8%。
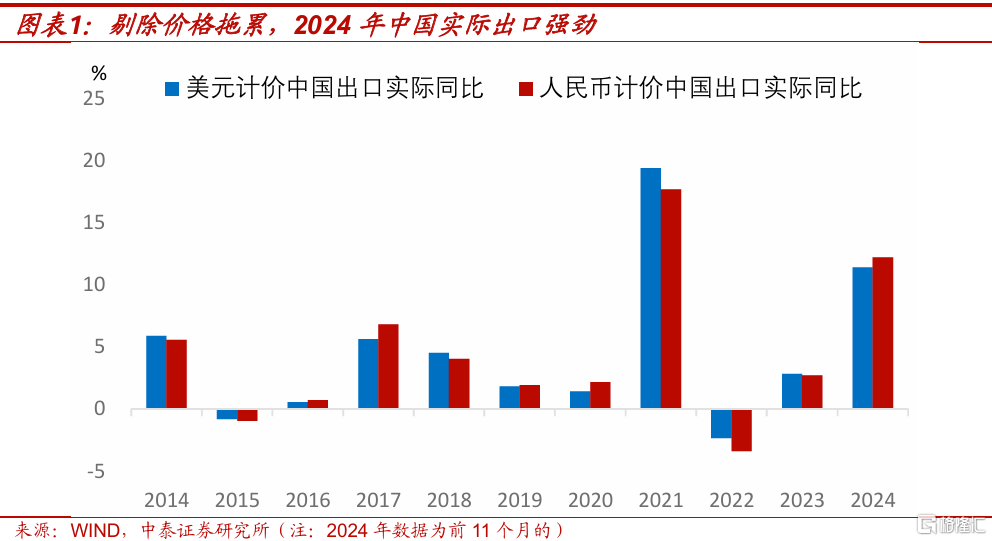
但和2021年支撐中國強出口的是外需強勁不同,2024年中國出口表現好,主要源於“以價換量”。2024年前三季度,中國以美元計價的貨物出口價格指數同比下跌7.1%,而同期全球平均的只同比下跌了1.1%。
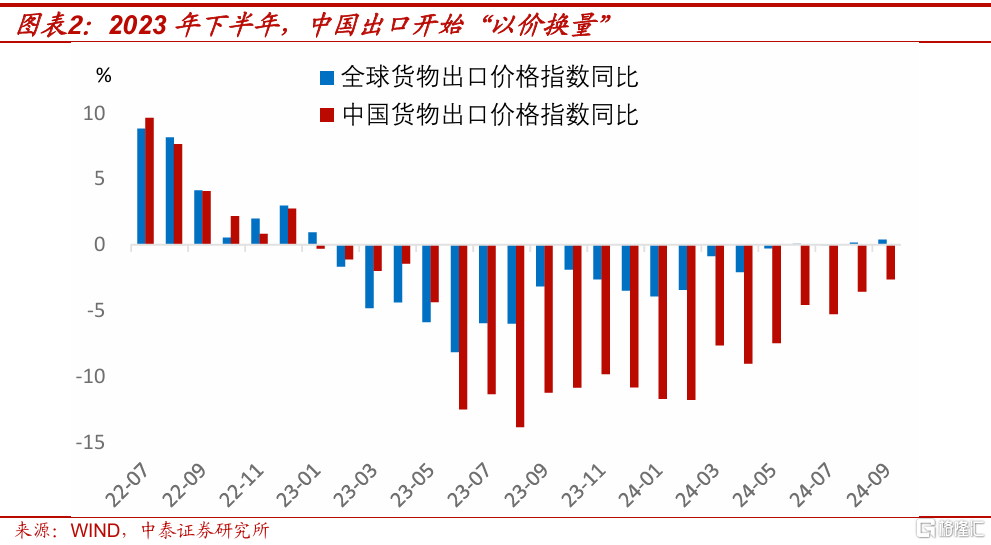
展望2025年,我們認爲這種依托價格優勢帶來的出口高增長,將面臨壓力。除了美國加徵關稅外,還需要警惕中國和新興市場國家貿易摩擦上升的風險。
特朗普將在2025年初出任美國總統,其曾聲稱要對從其他國家進口的產品加徵10%-20%的關稅,對從中國進口的產品加徵關稅至60%。故需要警惕2025年中美貿易摩擦升級,尤其是互加關稅的可能。
測算顯示,美國對華產品加徵關稅,對於美國CPI通脹的影響,可能不到0.3個百分點。
2024年三季度,美國自中國進口額佔美國總進口的比例爲13.5%,佔美國居民商品消費額的7.0%,佔美國居民總消費額的2.2%。加徵關稅會產生進口替代,《華爾街日報》援引牛津經濟研究院的測算,如果美國將從中國進口產品的關稅全面提高到60%,那么美國進口裏來源於中國的比例將下降到4%。按照從13.5%下降到4.0%等比例推算,如果美國對華產品全面加徵關稅,美國從中國進口額佔其居民消費比例,將從2.2%下降到0.7%。
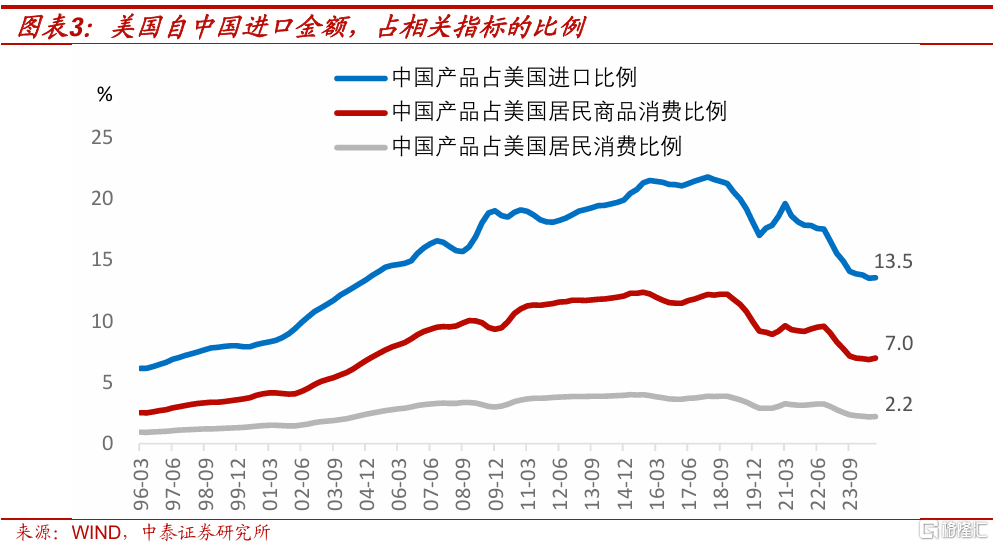
由於美國從中國進口的商品,除了消費品外,還有原材料和中間品,關稅升級後中國產品佔美國居民消費的實際比例將低於0.7%。CPI權重是根據典型消費者所消費的一攬子商品和服務的比例來確定,可以近似理解爲,此時美國CPI裏中國產品的權重將比0.7%更低。
彼得森國際經濟研究所(PIIE)的數據顯示,目前美國從中國進口的平均關稅爲19.3%。如果全面提高到60.0%,關稅平均增幅爲40.7個百分點。即使不考慮加徵關稅帶來的成本上升一部分會被企業承擔,按照前文計算的CPI權重上限0.7%來測算,對美國CPI同比的拉動也只有0.28個百分點。
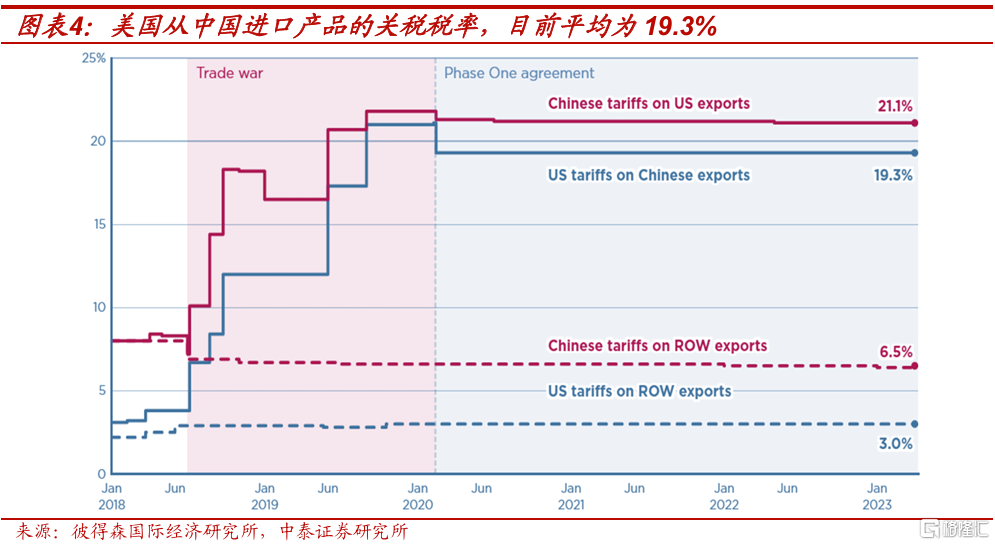
目前來看,2025年特朗普就任美國總統後,對華產品加徵關稅的節奏和力度,都有較大不確定性,也很難預測。但是從對美國通脹的影響程度看,兩國達成共識存在難度,需要客觀看待2025年中國對美出口的關稅風險。
市場對美國加關稅的討論比較多,我們認爲,2025年也需要警惕中國和新興市場國家之間貿易摩擦升級的可能。
過去幾年,中國的出口結構發生很大變化,增量主要來自於新興市場國家。2019年到2023年,佔中國出口比例靠前的國家和地區中,份額提升的有俄羅斯(+1.29%)、東盟(+1.12%)、非洲(+0.58%)、墨西哥(+0.56%)和印度(+0.49%)等新興經濟體,對美國、歐盟、日本、韓國等發達經濟體的出口比例均回落。

中國出口結構優化,降低了對發達經濟體的依賴。但需要注意的是,中國和新興經濟體產業結構的相似性,是要強於中國和發達經濟體之間的。換言之,中國和以東盟爲代表的新興市場經濟體之間,既有合作關系,也有競爭關系。
過去一年多的時間裏,中國出口價格指數降幅,顯著大於其他新興經濟體的。這意味着一些新興經濟體,除了要和中國直接競爭出口外,它們國內市場,也可能受到中國低價產品流入的影響。
2025年不排除一些新興市場國家,爲了保護本國產業,對中國部分產品加徵關稅的可能,這或將讓中國的出口環境進一步惡化。
將中國出口金額,拆分爲全球貨物貿易量×中國份額×中國出口價格,結果顯示2025年中國以美元計價的出口可能同比下跌3.3%左右。
全球貨物貿易量方面,2024年10月,WTO發布《全球貿易展望與統計報告》,其預計2025年全球商品貿易量將增長3.0%。考慮到特朗普就任後,全球的關稅風險將上升,我們假設2025年全球貨物貿易量增速下降到2%左右。
中國出口份額方面,2024年前三季度,中國出口金額佔全球比例爲14.5%,考慮到搶出口的推動,預計2024年中國全年出口金額的份額將提高到14.6%左右。測算顯示,2024年前三季度中國出口量佔全球的份額爲16.4%,假設2024年全年也是這個比例。
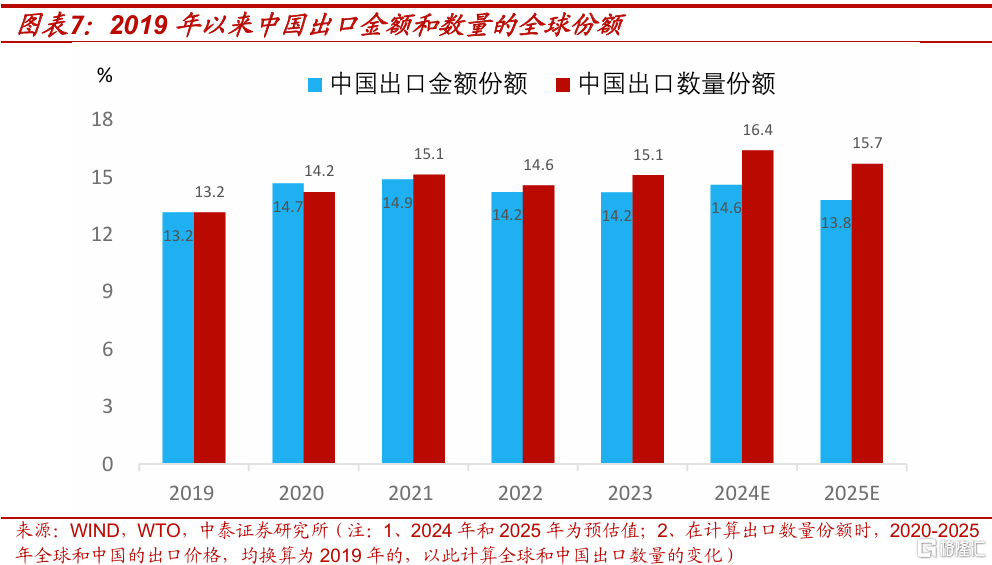
2025年中國出口面臨的外部環境惡化,假設中國出口數量的份額下降到15.7%。這是個偏樂觀的假設,因爲在2024年以前,中國出口數量份額歷史高點也只有15.1%。價格優勢下2025年中國出口數量,可以對衝一部分關稅的影響,使得訂單不至於快速從中國流出。另外加徵的關稅落地也需要時間,且在關稅落地前會有搶出口。
出口價格方面,2024年前三季度,中國出口價格指數同比下跌7.1%。考慮到基數效應等原因,假設2025年中國出口價格指數平均下跌1.0%。
根據上述假定,可以估算得2025年中國出口同比=1.02×0.157×0.99/0.164-1=-3.3%。其中,出口數量拖累2.3個百分點,出口價格拖累1.0個百分點。
2025年制造業:投資增速可能下降
2025年中國出口承壓後,國內的供需格局可能進一步轉弱,制造業投資高增長或難持續。
從國家統計局數據看,盡管今年實際出口同比兩位數增長,但工業產能利用率仍處於歷史低位。今年三季度,當季的工業產能利用率爲75.1%,處於2017年以來的同期最低水平。
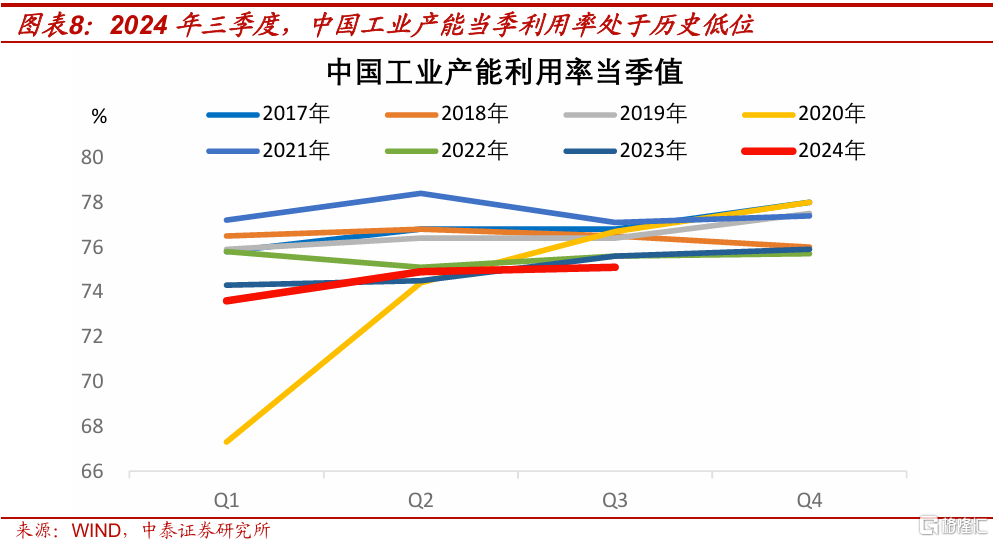
展望2025年,中國制造業部分子行業產能供過於求的局面或將持續。
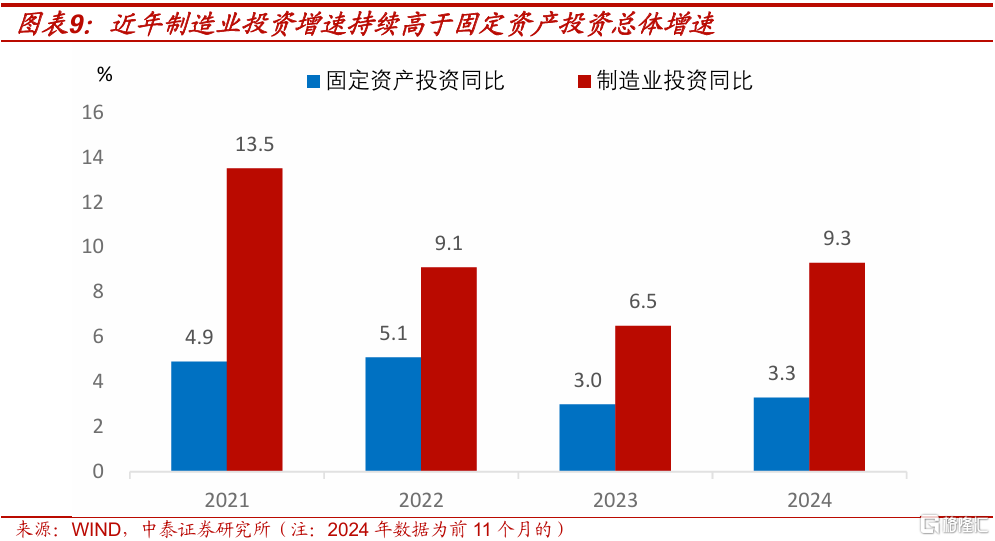
供給端看,一是過去幾年制造業投資高增長,所形成的產能將逐步釋放。2021年到2023年,以及2024年前10個月,中國制造業投資同比都高於同期固定資產投資總體的增速。由於制造業投資項目有建設周期,部分已开工但未完工的項目,產能可能在2025年逐步釋放。
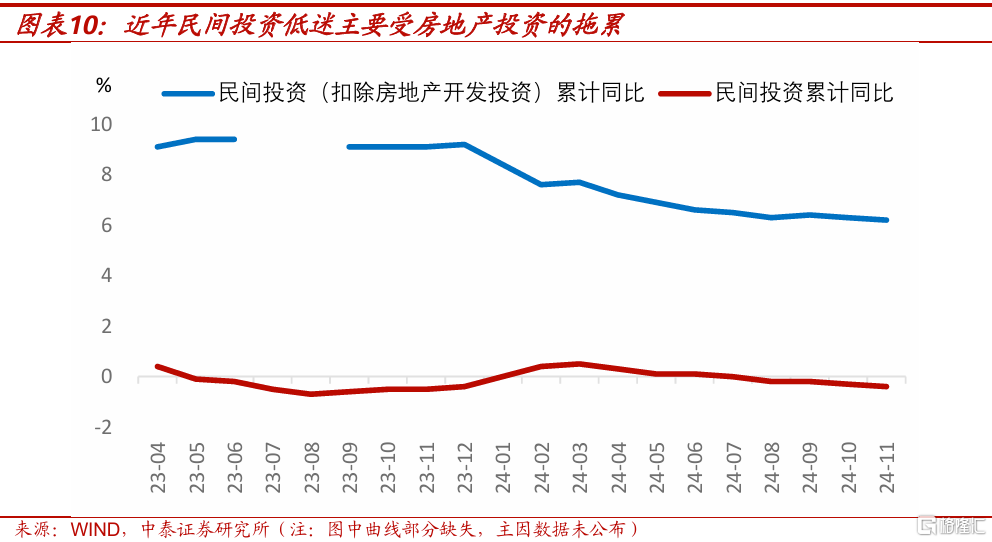
從民間投資增速,也可看出近年制造業投資表現不弱。民間投資同比轉負,是最近幾年全社會關注的重點話題之一。2023年和2024年前11個月,中國民間投資同比都爲-0.4%,這主要是房地產行業的拖累。剔除掉房地產行業的拖累後,民間投資同比分別爲9.2%和6.2%。
二是對比中國走出1998-2002年物價低迷的經驗看,當前供給端可能難以通過大規模破產來實現出清。
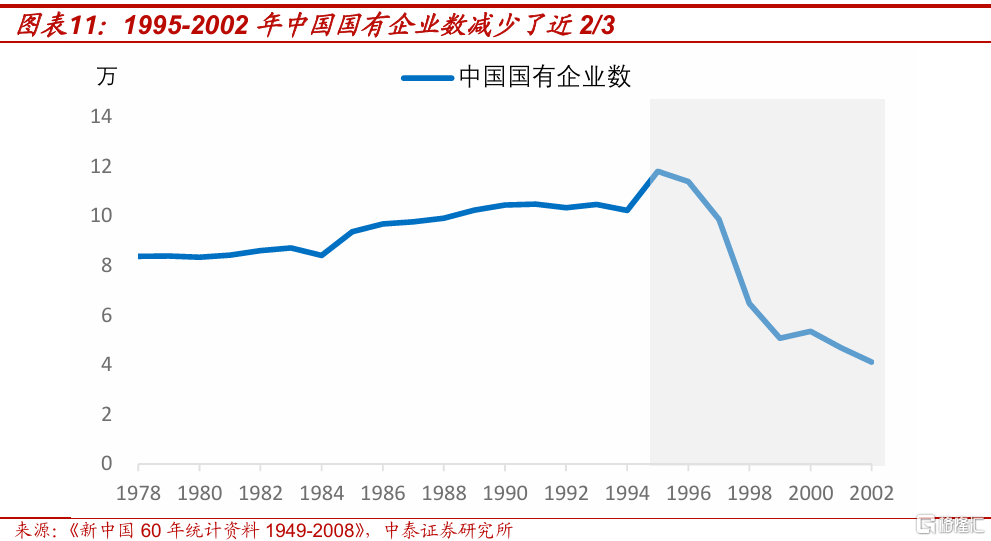
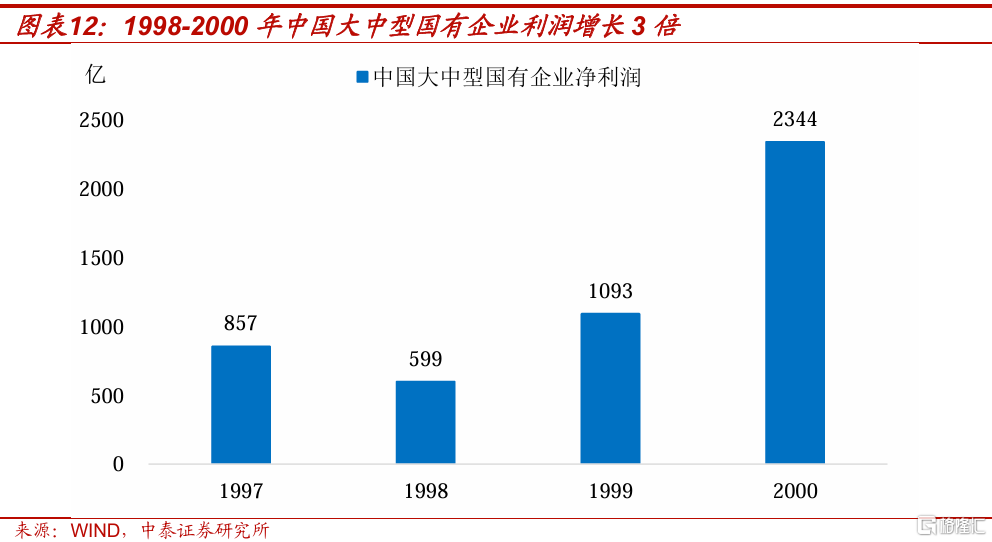
我們認爲,相比於1998年开啓房地產市場化改革、2001年12月中國加入WTO所帶來的需求擴張,當時國企改革背景下的大規模破產重組,對於走出低物價更重要。中國國有企業數量從1995年的11.8萬家,減少到了2002年的4.1萬家,七年時間裏減少了將近2/3,其中1998年就減少了3.4萬家。供給收縮使得中國大中型國有企業利潤從1998年的599億,快速提高到2000年的2344億,兩年時間裏增長了近三倍。
考慮到當前就業形勢,以及以新能源爲代表的部分行業過剩產能集中於民企,類似於1998-2002年這樣大規模破產來去產能的難度較大。結合近期政策來看,未來可能的方法,一是通過並購重組提升行業集中度,二是通過行業自律組織來號召企業減產。
在產能難以快速去化的背景下控產,一定程度上能夠緩解供給過剩壓力,但相比於讓企業直接破產,各類控產政策的效果大概率是要明顯弱一些的,這會壓制企業的新增資本开支意愿。
需求方面,外需走弱除了直接抑制出口高依賴度行業的制造業投資外,還會通過就業→收入→消費→投資的間接渠道拖累制造業投資。
先來看出口對制造業投資的直接影響。2024年1-10月,出口交貨值佔行業營收比例超過15%的制造業子行業有12個,2023年這12個子行業的固定資產投資,佔當年制造業總投資的45.6%。其中,計算機、通信和其他電子設備制造業,電氣機械器材制造業這兩個行業,2023年投資佔制造業總投資的比例都超過10%。根據國家統計局公布的累計投資同比,可以測算出2020年-2024年11月這兩個制造業子行業的投資額分別增長了99.0%和108.1%,強出口是它們過去幾年投資高增長的重要支撐。
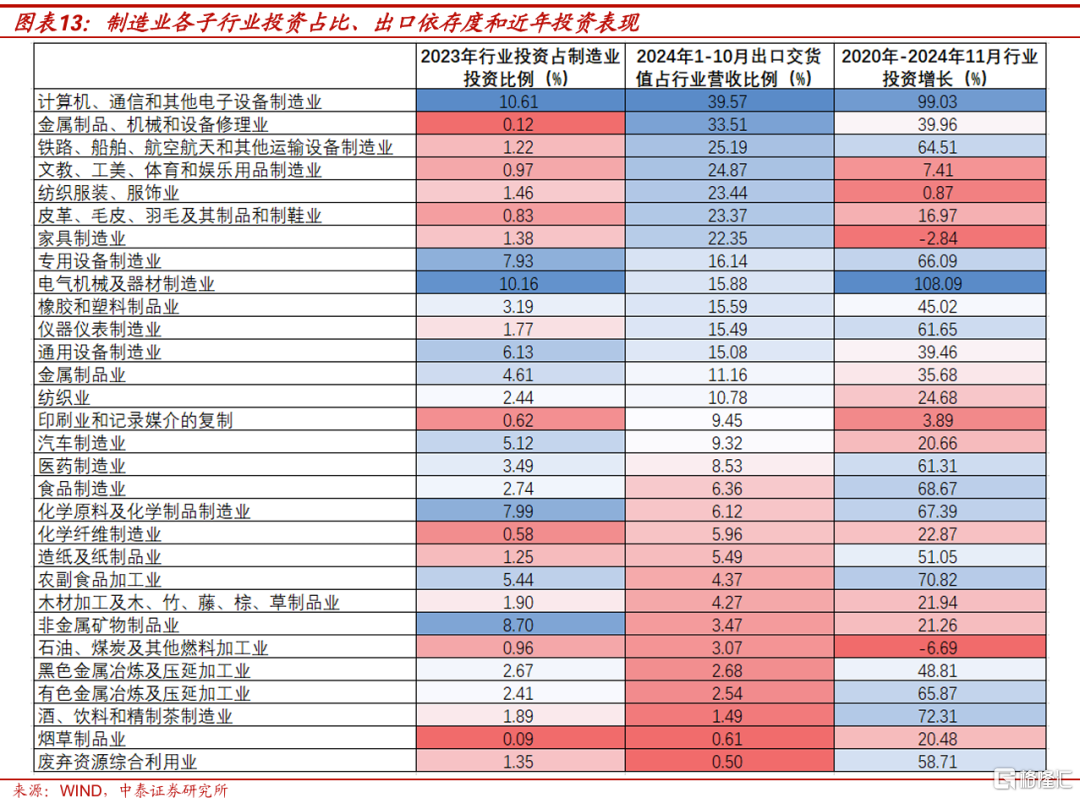
如果將2024年前10個月(最新數據),出口交貨值佔營收比例超過15%的行業,定義爲高出口依賴度行業的話,可以發現2020年以來,出口對制造業投資有正向影響。2020年1月到2024年11月,出口高依賴度的12個制造業子行業,投資累計增長62.3%,而非高出口依賴度的其他制造業子行業,同期投資增長了42.4%。
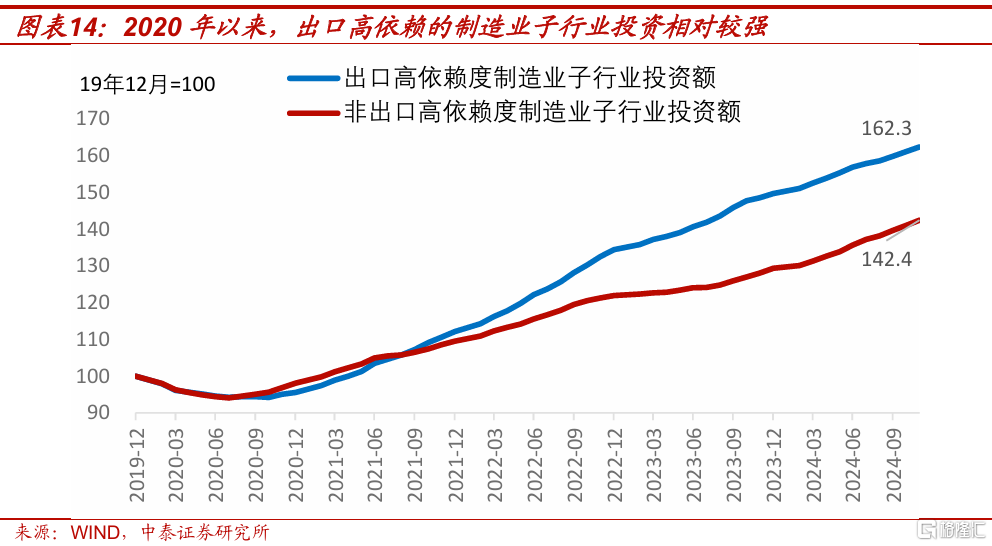
因此,如果2025年中國出口轉弱,且企業預期外部環境短期難以改善的話,預計將會對制造業投資產生負面影響。
再來看出口轉弱對制造業投資的間接影響。2020年10月,商務部外貿司負責人談2020年1-9月中國外貿情況時,提到外貿帶動就業人數達1.8億。當年年末全國就業人員7.5億人,外貿帶動的就業佔比24%。由於近年剔除價格拖累後的實際出口高增長,外貿帶動的就業佔比可能進一步提升。外需走弱後,穩就業難度可能上升,會拖累相關產業鏈就業人員的收入和消費,進而向下遊消費品制造業的投資傳導。
因此,從供需、預期等視角,2025年中國制造業投資或面臨一定壓力。
值得關注的增量是,2025年制造業大概率會和近幾年一樣,在逆周期調節中“基建化”,即扮演越來越重要的角色,存量設備更新、國產自主可控等領域,有望獲得信貸、財稅和產業等政策的支持。不過這些政策,可能難以對衝企業自發性的資本开支意愿下降,預計制造業全年投資同比,將從2024年的9.4%左右,下降到2025年的5.0%左右。
房地產:2025年銷售跌幅有望收窄
預計2025年中國房地產銷售面積同比跌幅有望收窄,但房地產投資可能仍是中國經濟的重要拖累。低基數下,預計銷售面積同比跌幅有望回升到-5.0%,但房地產开發投資同比可能仍在-10.0%左右。
2024年前11個月商品房銷售面積同比爲-14.3%,假設2024年全年也是這個增速的話,可估算得2024年商品房銷售面積爲9.58億平米,較2021年的歷史高點下降了46.6%,接近腰斬。
盡管如此,我們認爲2025年中國商品房銷售面積同比回正,還是會面臨一定壓力,主要有以下三個原因:
首先,中國居民部門實際償債壓力高於主要發達經濟體,外需走弱後,可能會通過就業、收入和預期的渠道,抑制居民購房意愿。
測算顯示,2024年一季度(國際可對比的最新數據),中國家庭部門可支配收入用於還本付息的比例爲13.5%,高於英國、美國、日本、法國和德國等主要發達經濟體。今年10月新一輪存量房貸利率下調,帶來的年化利息支出減少1500億,使得可支配收入用於還本付息的比例下降約0.3個百分點,但中國家庭部門的償債壓力仍高於上述主要發達經濟體。
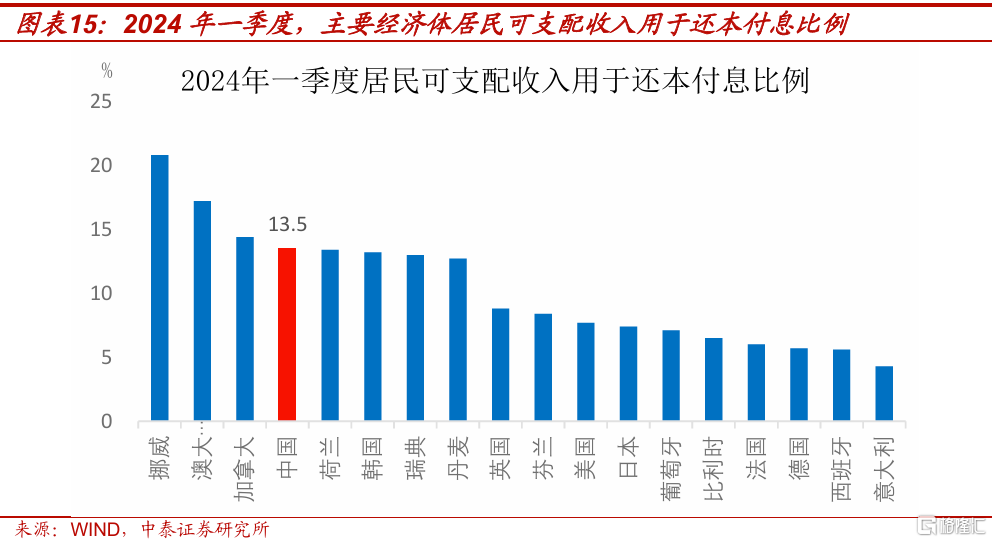
這是近年壓制居民購房和消費的核心原因之一。考慮到2025年中國出口所面臨的壓力,以及出口轉弱向相關產業鏈就業和收入的傳導,居民償債壓力短期明顯緩解的可能性相對有限,購房意愿或再度轉弱。
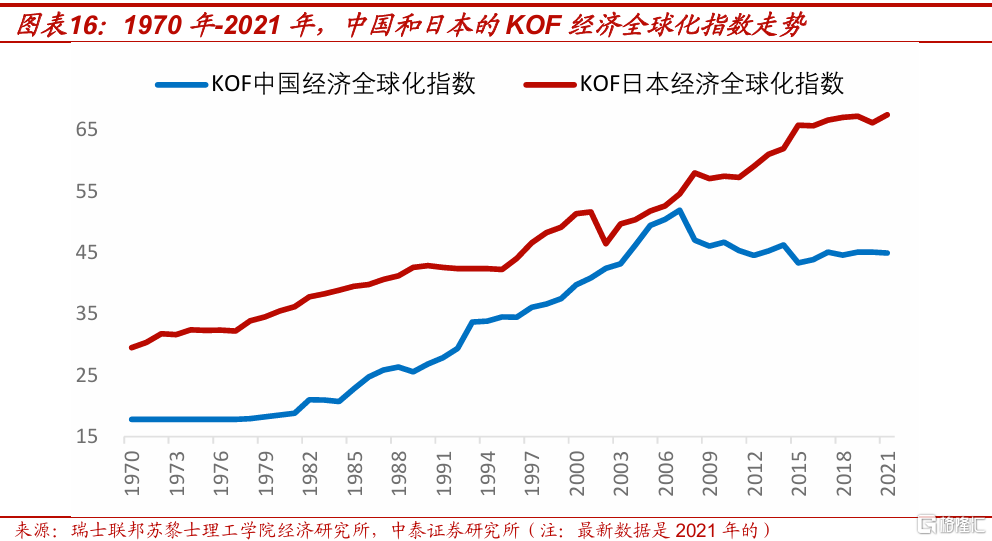
另外需要注意的是,對未來的預期,也是影響居民購房的重要因素。出口產業鏈涉及的就業人數衆多,外部環境如何,也是影響居民預期的關鍵變量。從瑞士聯邦蘇黎士理工學院經濟研究所公布的KOF全球化指數看,當前中國面臨的全球化環境,要弱於泡沫破滅初期的日本,當時由於蘇聯解體、冷战結束,全球化迎來加速的拐點。如果2025年中國面臨的貿易摩擦升溫,可能也會影響居民預期,進而給購房意愿帶來負面影響。
其次,保交樓進展,會影響居民購买新房的積極性,建議關注專項債收儲土地和收購存量商品房政策的效果。如果增量政策改善房企現金流和推進保交樓的效果低於預期,2025年居民對新房尤其是期房可能仍持觀望態度。
2016年年初到2021年上半年,房屋新开工面積(12MA,即12個月移動平均)同比,領先於竣工3年左右。2021年三季度开始,由於开發資金來源同比轉負,上述領先性开始轉弱,可以理解爲开發商現金流變得緊張後,影響了在建項目的施工,應該竣工和交付的商品房面積持續累積。在政策推動下,2023年保交樓加快,全年竣工面積同比爲17.0%,但2024年竣工面積同比又大幅回落,前11個月爲-26.2%。
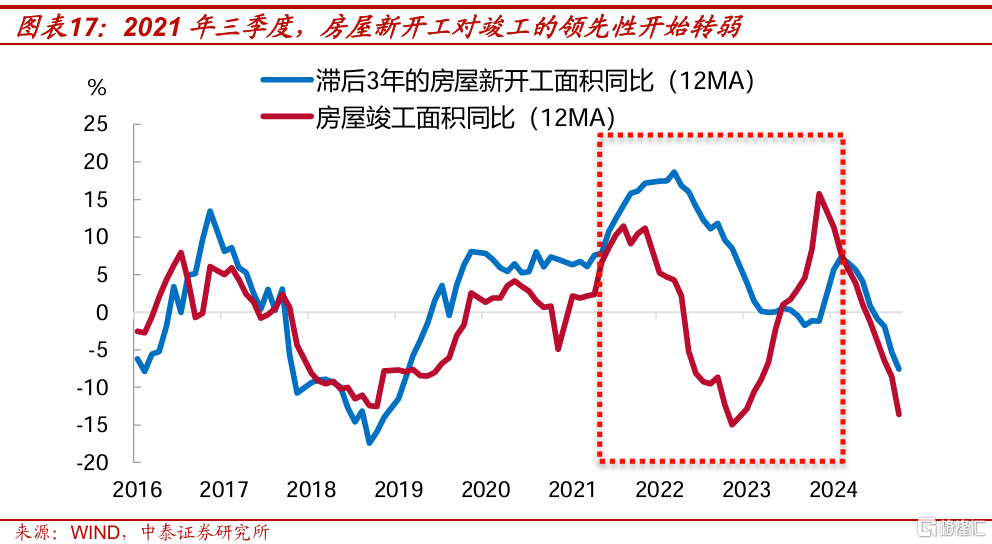
根據上述領先-滯後關系,估算得2021年7月到2024年11月,應竣工但實際未竣工的商品房面積爲2.7億平方米。
需要說明的是,上述測算只考慮开工滿三年但實際未竣工和交付的商品房。由於一些开發商破產倒閉了,它們的項目开工到現在可能不滿3年,但也屬於大衆所理解的爛尾樓範疇裏,實際需要保交樓政策支持的商品房面積,要大於我們的測算結果。
對於項目能否如期交付的擔憂,2025年預計將繼續是居民購房時的重要顧慮。通過專項債等資金收儲土地和收購存量商品房,這些政策的效果如何,對於房地產市場能否形成良性循環有重要影響。
最後,2016年-2024年中國住宅銷售,預計將合計透支6.1億平方米,這從供給和需求兩端,增加了商品房銷售回暖的難度。
我們將合理的住宅銷售面積,拆分爲剛需和改善型需求,2008年到2015年合理的銷售面積,和實際銷售面積基本同步。2016年房價上漲,帶動投資性和投機性的住宅購买需求上升,透支一直持續到2021年。2022年和2023年,合理銷售面積連續兩年低於實際的,其中2023年缺口爲3.2億平方米,預計2024年缺口將達到4.4億平方米。
綜合計算,2016年-2024年中國住宅銷售合計透支約6.1億平方米,約佔2024年全年住宅銷售面積的76%。
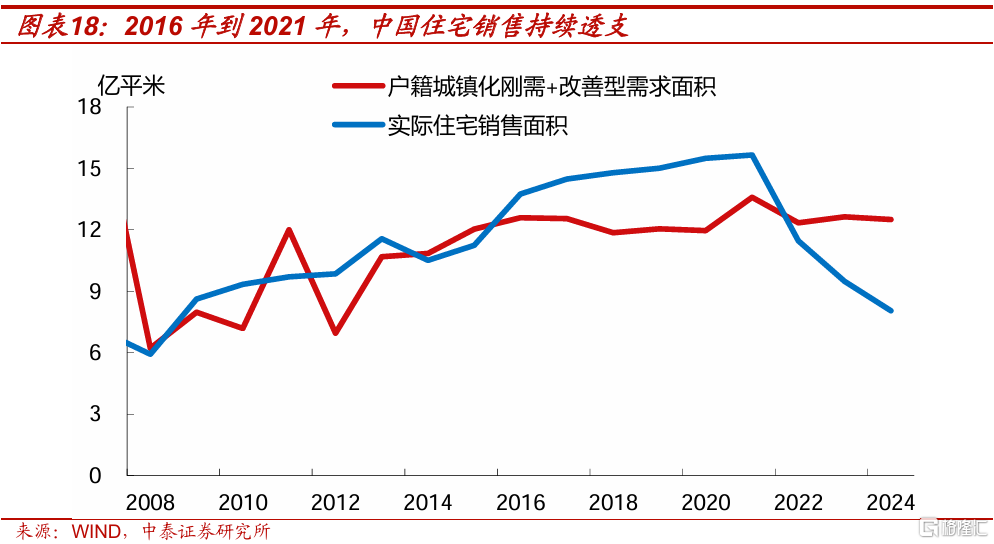
對於新房市場而言,過去幾年的大規模銷售透支,從供給端看,會繼續變成二手房掛牌,擠壓新房銷售;從需求端看,過的去透支對於當前購房本來就是利空,在房價升值預期較弱時更是如此。
總的來說,我們認爲盡管當前商品房銷售已明顯低於合理水平,但考慮到居民債務壓力、預期有待改善、存量未交付樓盤較多和過去幾年的銷售透支,2025年商品房銷售面積同比轉正有一定難度,預計全年在-5%左右。
宏觀視角看地產,各類指標中,房地產投資完成額非常關鍵,下面我們來分析2025年的房地產投資。房地產投資完成額可以拆分爲建安投資和土地購置費用,其中建安投資取決於施工面積,土地購置費用受开發商拿地和繳款節奏的影響比較大。
先來看2025年的施工面積。施工面積=上期末施工+本期新开工-本期淨停工,假設2024年全年的房屋新开工面積、施工面積和竣工面積的同比增速,持平於前11個月的-23.0%、-12.7%和-26.2%,那么可估算得2024年全年經停工面積爲8.0億平方米。假設在專項債等資金的支持下,2025年淨停工面積下降至7.5億平方米。
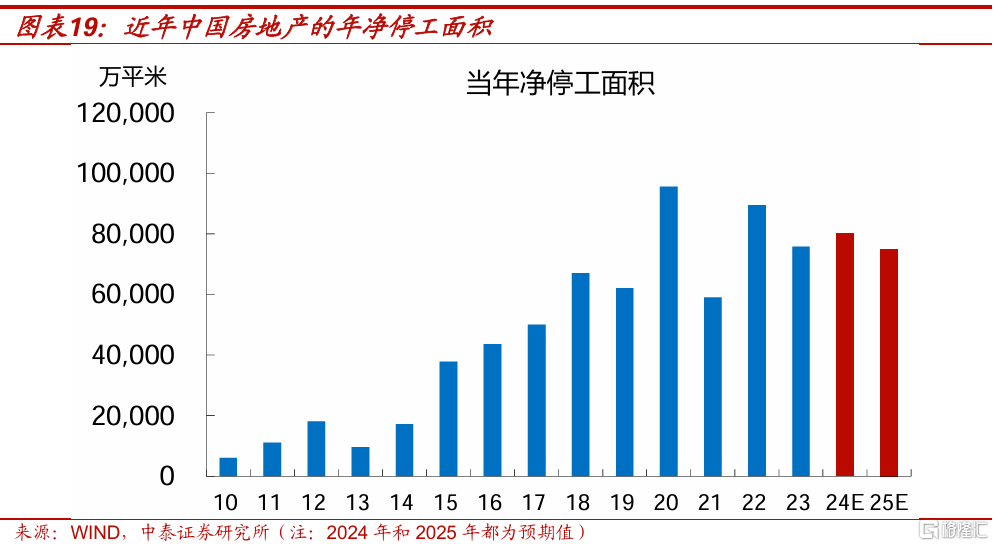
在偏樂觀的假設下,2025年全年的新开工面積同比,由於低基數回升到-15.0%,那么全年施工面積同比,也只是從2024年的-12.7%,小幅回升到-11.8%。因此我們預計,2025年建安投資的同比跌幅可能和2024年接近。
和直覺差距較大的主要原因是,施工面積會受到以前年份新开工項目的傳導。2019年是中國房地產新开工面積的歷史高點,到2024年已連續5年下降,累計降幅達到了68%,近年新开工面積持續下降,會對2025年的施工面積形成拖累。
土地購置費用方面,2022年、2023年和2024年前10個月的同比,分別爲-5.7%、-5.5%和-7.8%。考慮到銷售面積仍在探底,以及2024年中央經濟工作會議要求“合理控制新增房地產用地供應”,預計2025年土地購置費用的同比降幅可能和今年接近。
綜合上述分析,我們預計2025年中國房地產投資同比可能在-10%左右,跟2024年的基本持平。主要原因是,過去幾年的新开工持續下降,會向2025年的施工和面積傳導。
2025年經濟結構再調整
——公共消費與基建將是亮點
前文討論了2025年中國出口、制造業和房地產投資的趨勢,可以看到出口是最關鍵的變量,出口走弱除了直接拖累總需求外,還會影響制造業投資和房地產市場形成良性循環的難易程度。
爲保持經濟平穩運行,政策有必要聚焦於加力擴大內需。2024年中央經濟工作會議,將全方位擴大國內需求,作爲2025年各項工作的首位。大力提振消費,以及適度加力基建投資,都將是擴大內需的重要抓手。
消費方面,客觀來講,2025年內生修復的動能可能並不強。消費既是重要的增長動能,素有經濟“壓倉石”之稱,又是經濟的結果,受就業、收入、預期、債務等多重因素的影響。在分析出口和房地產時,已經討論了就業、收入、預期和債務這幾個變量,2025年它們對消費的促進作用,較2024年的邊際增量或有限。
還需要注意的是,2024年消費品以舊換新政策,可能會帶來一部分原本將在2025年釋放的置換需求,提前到2024年了。通過時間序列數據,可以看到國家統計局公布的限額以上消費中,家用電器和音像器材類、汽車類這兩個品類的零售額當月同比,2024年9月-11月增速中樞明顯上移。
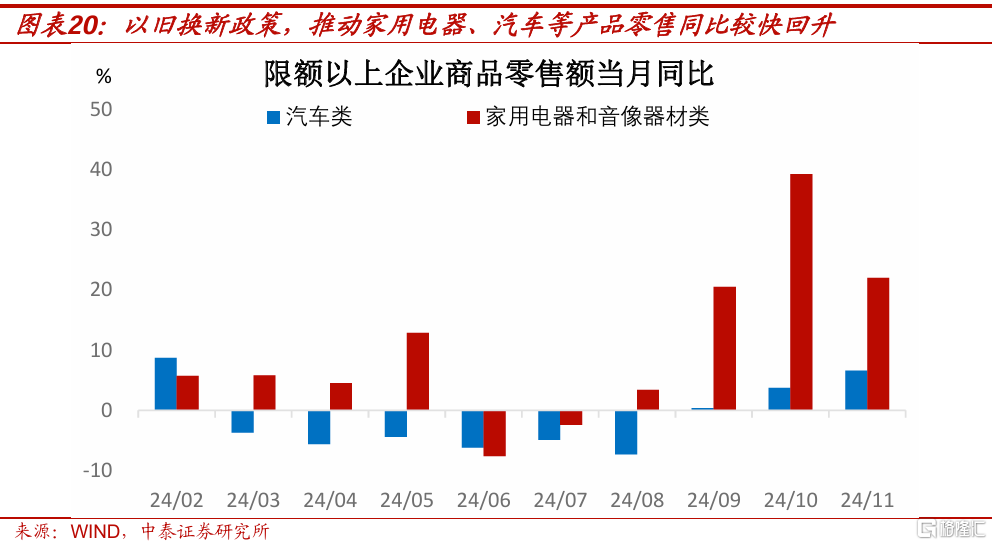
商務部數據顯示,截至2024年12月13日零時,消費品以舊換新政策整體帶動相關產品銷售額超1萬億元。主要商品中,汽車以舊換新帶動乘用車銷售量超520萬輛,其中報廢更新超251萬輛,置換更新超272萬輛。家電以舊換新帶動8大類產品銷售量超4900萬台。家裝廚衛“煥新”帶動相關產品銷售超5100萬件。電動自行車以舊換新帶動新車銷售近90萬台。
2023年中國社會消費品零售總額爲47.1萬億元,消費品以舊換新政策帶動零售額超1萬億元,對2024年全年社會消費品零售總額同比,有2.1個百分點的正向拉動。這既會使得部分置換需求前置,又會推升2024年的基數。
毫無疑問,2025年通過財政政策加力,來對衝家庭和企業部門的消費需求不足,非常有必要。國際對比看,中國通過優化財政資金投向,去支持消費恢復也有較大的提升空間。
世界銀行數據顯示,中國公共消費率,長期低於全球平均水平。公共消費率指的是,政府最終消費支出佔GDP比例。國際對比看,我國政府部門的經濟參與度較深,但用於公共消費的政府支出佔GDP比例,反而低於全球平均水平,政府主導的投資,可能擠佔了一些原本可用於公共消費的財政資源。

全球公共消費率,最新數據是2022年的,2020年-2022年中國公共消費率,平均比全球的低0.8個百分點。2023年中國名義GDP爲126萬億,假設中國公共消費率回升到全球平均水平,中國公共消費每年還有約1萬億的提升空間。
我國最終消費對GDP貢獻偏低是一個長期存在的現象,無論與全球發達經濟體還是新興經濟體相比,貢獻率均偏低,大致都在55%以下,相比美國的80%和印度的70%,仍有不小差距。相應地,投資(資本形成)對GDP的貢獻率大約是全球平均水平的兩倍,即便當2021年房地產出現下行周期後依然如此。
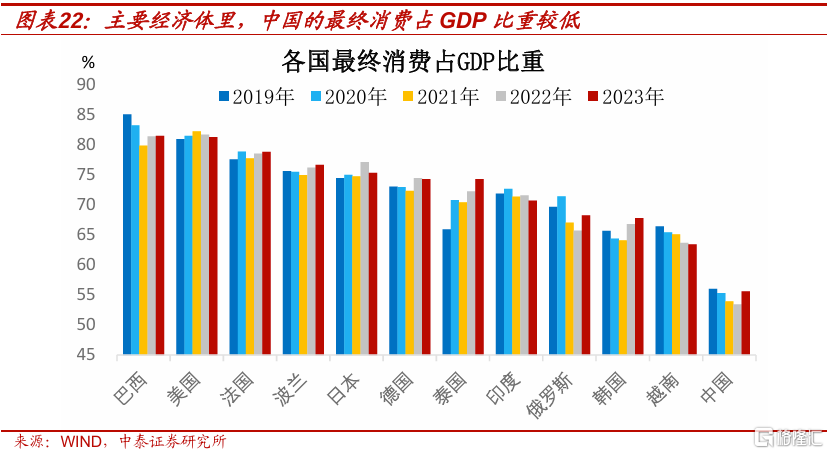
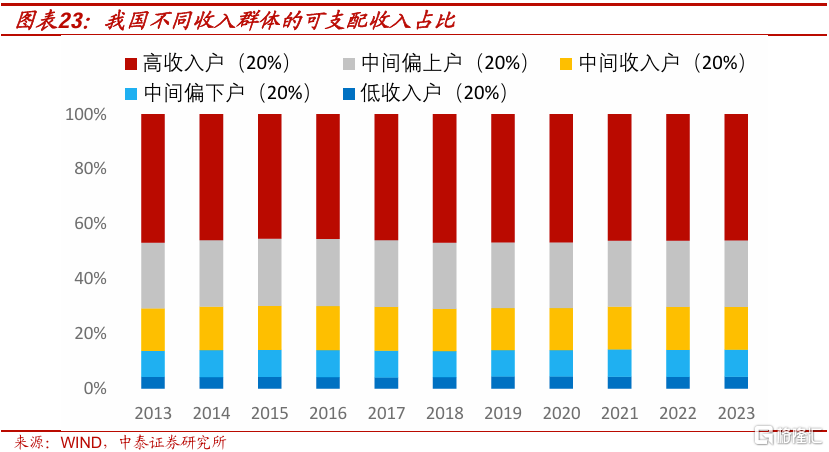
消費貢獻率偏低的根本原因在於居民部門的可支配收入佔GDP的比重偏低,全球平均水平大約在60%左右,我國按國家統計局的抽樣調查數據,大約只有45%左右。故直接和間接提高居民部門收入是提振消費的關鍵。
基於托底經濟的必要性,以及優化支出投向所帶來的提升空間,大力提振消費將是2025年擴大內需的重點工作。可能的方向:
一是擴大消費補貼的力度和範圍,比如將家居、消費電子等產品納入以舊換新政策的支持範圍,以及加大消費券投放力度等。中央經濟工作會議,也明確指出“加力擴圍實施‘兩新’政策”;
二是適當加大對特定困難群體的轉移支付,比如多胎家庭、已畢業但沒有找到工作的大學生等。和近年促消費的政策思路相比,2024年中央經濟工作會議更注重通過收入增長,來提高居民消費的意愿和能力;
三是加大財政資金對教育和社保等領域的投入,增加公共消費投入,這有助於釋放居民消費需求。
促消費節奏上,預計會根據經濟和物價等指標的變化,來動態調整。政策托底下,預計社會消費品零售總額全年同比,將從2024年的3.5%左右,提高到5.0%左右。
由於消費是一個慢變量,提振消費需要作長期努力,即進一步改善收入結構,按照二十屆三中全會提出的收入分配目標,即提高居民收入佔GDP的比重,並逐步降低經濟增長對投資的依賴度。
國民收入再分配改革是提振消費的重要舉措,實際上是在共同富裕的目標下,通過推進二次分配和三次分配來增加中低收入群體在收入分配中的佔比,從而起到提振消費的作用。如目前佔我國人口60%(包括中等收入、中低收入和低收入三組)的居民家庭的可支配收入佔整個居民部門的收入佔比只有31%,如果能夠擴大中產群體數量,每年該群體的收入佔比提高至1%,則對提振消費作用巨大,即假設該群體增加1%的平均消費傾向爲60%,而高收入和中高收入群體的佔比相應減少1%的平均消費傾向減少10%,則在居民可支配總收入不變的情況下至少每年可帶來超過2500億元的消費增量。
因此,當前消費偏弱現象並不僅僅是一個周期下行的問題,更是一個結構性問題,即需要堅持不懈促改革、調結構。正如中央經濟工作會議所提出的那樣,發揮經濟體制改革牽引作用。
考慮到2025年穩增長的目標,基建投資方面仍將維持較高增長。盡管從投資回報率的角度看,當前應該壓縮基建投資。但從對衝出口和地產走弱、托底經濟的角度看,2025年對基建投資依然有較高依賴,預計全口徑基建投資同比,將從2024年的9.5%左右,回升到11%左右。
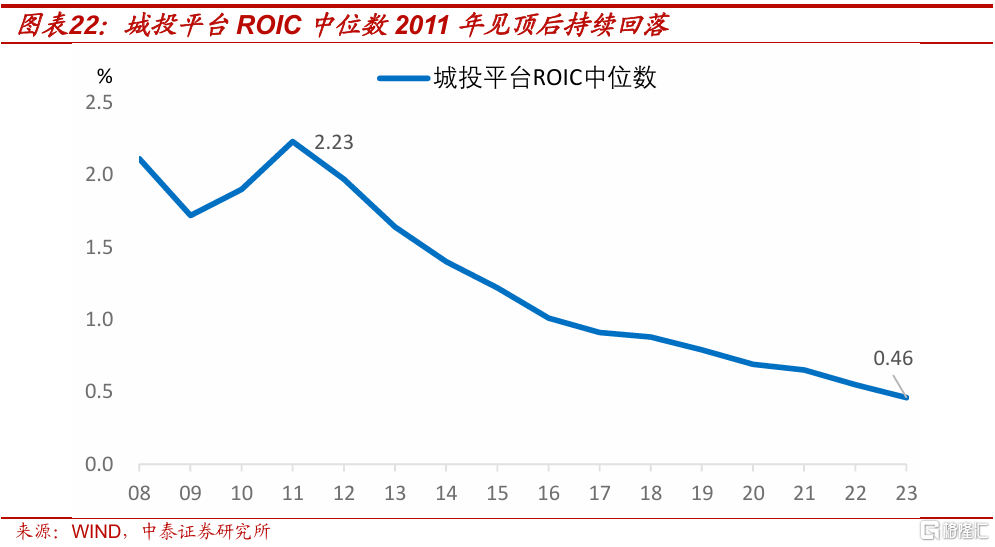
如果看投資回報率,大規模基建投資的性價比逐年下降。基建項目種類繁多,很難量化測算每年基建投資的回報率。考慮到城投公司在基建投資裏扮演了重要角色,我們以發債城投的資本回報率(ROIC)中位數,作爲基建投資回報率的替代指標。
數據顯示,2011年是中國發債城投ROIC中位數的歷史高點,爲2.23%,此後逐步回落,2023年已下降到0.46%。這個趨勢跟中國實際GDP增速的走勢大體一致,反映了經濟增長放緩後,基建等固定資產投資的回報率也隨之下降。
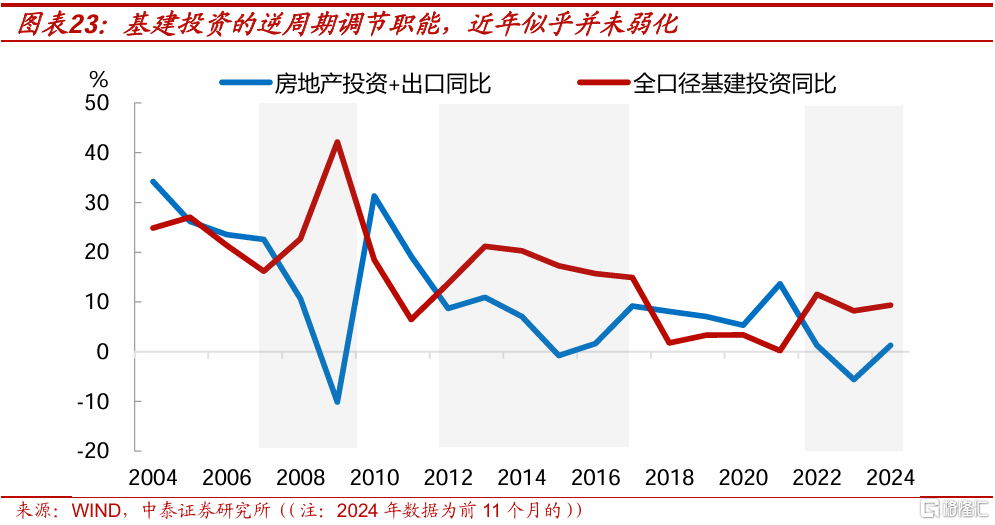
但與此同時,當終端需求不足,尤其是出口+地產這兩個增長動能轉弱時,又需要通過基建投資來托底經濟。即使在隱性債務高壓監管的2022年到2024年,也依然如此。對比歷史看,似乎基建投資的逆周期調節職能,並未隨着GDP增速中樞下移和經濟轉型而弱化。
這背後的可能原因,我們認爲有兩點:
一是中國GDP增速目標具有連貫性,當終端需求不足時,爲避免經濟增長增速大幅波動,需要通過基建投資來托底經濟。2012年到2024年,除受外生衝擊嚴重的2020年未設GDP增速目標外,其余年份的目標要么持平於上年,要么是下調0.5個百分點,這使得在正常年份GDP增速不能出現大幅下滑。
當全社會進一步淡化了對GDP增速的關注,或者經濟內生增長動能到達新的穩態時,基建投資的逆周期調節職能才有望被弱化。
二是相比於消費等其他穩增長手段,政府主導的基建投資效果更快。基於諸多非經濟層面的因素考慮,各級政府往往也更有動力去推動基建投資,而非促消費。
2025年中國出口承壓,地產延續低迷,托底經濟對基建投資的訴求,大概率將高於2024年。中央經濟工作會議指出,2025年的新增赤字、超長期特別國債、新增專項債,規模較2024年都將上升,財政資金有望加大對基建投資的支持。化債和專項債收儲土地,有助於緩解部分城投平台的現金流壓力,這對基建投資而言也屬於邊際利好。
中央經濟工作會議,在擴大投資部分,提到“加強財政與金融的配合,以政府投資有效帶動社會投資”。除了在利率債供給上升時提供流動性支持外,關注是否會類似於2022年,通過政策性开發性金融工具這樣的創新性工具,來支持重大項目,這可能是“超常規逆周期調節”的着力點。
基建的重點投向,預計將延續2024年的思路:一是水利管理業,2024年前11個月水利管理行業投資同比增長40.9%,水利領域補短板是近年重要工作;二是電力、熱力的生產和供應業,主要支撐是能源轉型和電網建設;三是物流倉儲業,尤其是城鄉冷鏈運輸相關的,專項債資金可用於相關領域的投資;四是在城市更新和舊城改造的帶動下,城市道路、給排水等公共設施管理業的投資增速有望回升。
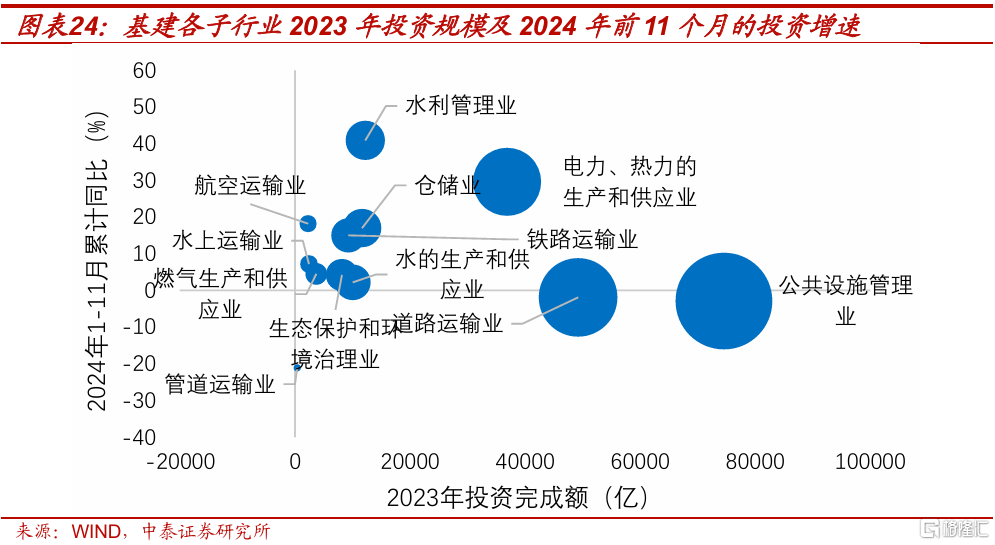
在地緣政治不確定因素日益增多的背景下,和大安全相關的基建投資,2025年也可能獲得更多財政資金支持。它們的收益率考核要求相對偏低,若其它終端需求出現了超預期走弱,安全相關基建項目可能較快上馬來托底。
物價:低位運行趨勢預計將持續
截至2024年三季度,中國GDP平減指數已連續6個季度同比爲負。從PPI同比來看,物價低迷在四季度呈現加速之勢。
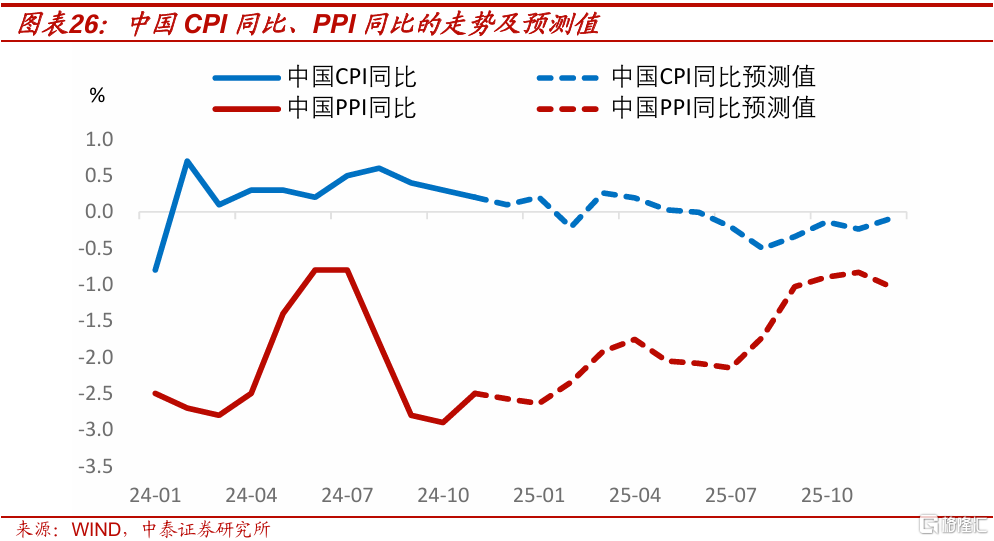
展望2025年,我們認爲可能難以走出低物價。低基數下,預計全年PPI同比將從2024年的-2.2%,回升到-1.7%;全年CPI同比,將從2024年的0.3%,下降到-0.1%。
先來看PPI。截至2024年11月,中國PPI同比已連續26個月同比負增長。2025年出口轉弱後,國內工業品供過於求的局面將更嚴峻,在制造業投資和出口部分,我們已做了相關分析。
此外需要注意的是,出口價格同比的彈性,通常要大於國內PPI同比的。2023年7月至今,出口價格指數同比,就持續低於中國PPI同比。2025年出口轉弱後,一部分原來通過低價搶出口的產能,可能會回來卷國內市場,這加大了PPI同比回正的難度。
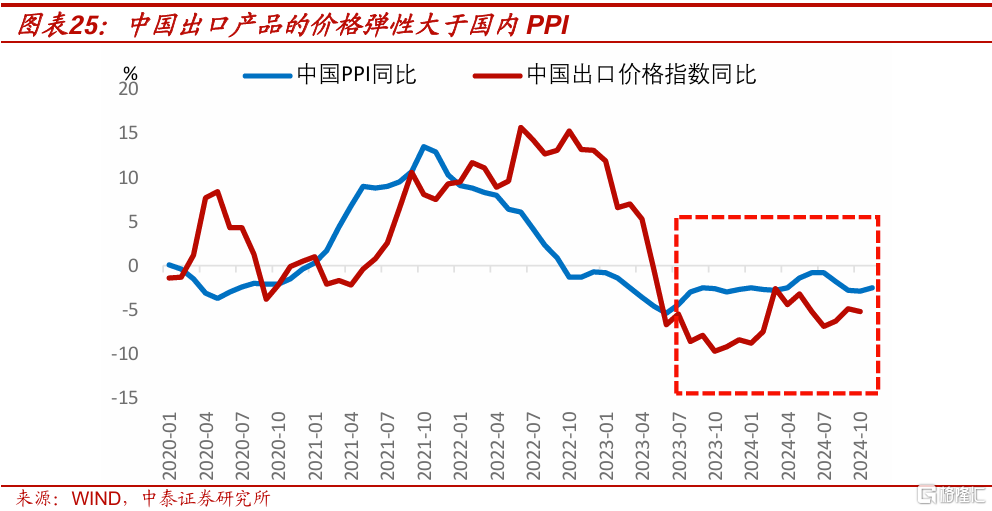
再來看CPI。根據對CPI的影響程度,主要分析四部分:
一是豬肉。2024年5月到10月,能繁母豬存欄量已連續半年上升,根據能繁母豬補欄到生豬出欄一年左右的生物周期推算,預計2025年生豬供應的壓力不大。在終端消費偏弱的情況下,豬肉漲價壓力有限;
二是油價。特朗普就任後,俄烏、巴以等地緣事件對原油供應的擾動可能下降,加上特朗普對傳統化石能源的支持態度,2025年國際油價中樞預計將下移。2024年12月10日,美國能源信息署發布月度展望報告,預計2023年到2025年,布倫特原油期貨的平均價格,分別爲82美元/桶、81美元/桶和74美元/桶,即2025年國際油價的同比跌幅將擴大;
三是工業消費品。它的邏輯和PPI一樣,出口轉弱後國內供過於求更明顯,且低價出口產品可能會回來卷國內的市場;
四是服務消費。相比於商品消費,服務消費的彈性更大,出口產業鏈就業和收入壓力,在抑制服務消費的同時,還會通過勞動力從制造業向服務業轉移的渠道,在成本端利空服務價格。
我們對2024年12月到2025年12月,中國CPI同比和PPI同比的月度值做預測,結果如下圖所示。
2025年經濟政策展望
2024年中央經濟工作會議,定調“實施更加積極的財政政策和適度寬松的貨幣政策”,也把保持就業總體穩定列爲2025年宏觀調控的目標之一,相關政策值得期待。
財政政策方面,財政部藍部長曾表示“中央財政還有較大的舉債空間和赤字提升空間,可以爲逆周期調節提供更多的政策工具”。2024年中央經濟工作會議指出,提高財政赤字率、增加發行超長期特別國債、增加地方政府專項債券發行使用,財政加力支出來對衝外部環境變化對中國出口的拖累。
預計2025年廣義財政赤字將有3萬億左右的增量,從9.0萬億左右提高到12萬億左右,對應的廣義赤字率從7%左右提高到9%左右。具體的測算過程如下:
一是預計2025年狹義財政赤字率在3.5%-4.0%,對應的狹義財政赤字在4.8萬億-5.5萬億。目前看,預算赤字率爲4%這一上限的可能性比較大。
二是新增專項債額度在5萬億左右。2024年中央經濟工作會議,在增加地方政府專項債券發行使用的同時,指出要擴大投向領域和用作項目資本金範圍。盡管中央經濟工作會議,沒有提到用專項債收儲土地和回購商品房,但12月16日國常會,指出“允許專項債用於土地儲備、支持收購存量商品房用作保障性住房”,我們認爲2025年可能落地。
加之要通過擴大投資來應對特朗普上台後中國出口走弱的風險,2025年新增專項債額度可能在5萬億左右。如果狹義財政赤字率在3.5%的話,新增專項債額度可能要超過5萬億。狹義財政赤字和新增專項債的組合,要等到2025年兩會才能確定。
2025年用於化債的2萬億專項債額度,已經在今年11月下發,因此不會佔用2025年的新增額度。
三是超長期特別國債,預計規模在2萬億或以上。2024年的超長期特別國債規模爲1萬億元。根據10月12日財政部領導在國新辦新聞發布會上的介紹,將發行特別國債支持國有大型商業銀行補充核心一級資本。我們預計補充資本金的規模在1萬億左右,因此2025年的超長期特別國債規模可能要達到或者超過2萬億,也可能達到3萬億。
綜合上述三點,粗略估算,預計廣義財政赤字率將從2024年的9萬億左右,提高到12萬億左右,對應的廣義赤字率從6.6%提高到8.8%。財政政策在應對外部環境變化時,發揮了積極作用。不過,除去2.8萬億的爲償還隱性債務的專項債、預期1萬億的銀行補充資本金以及支出債務利息之後,廣義的實際增量赤字規模增加並不多。故要穩預期還得繼續出台“超常規的逆周期調節政策”。
對於2025年的貨幣政策,有以下四個判斷:
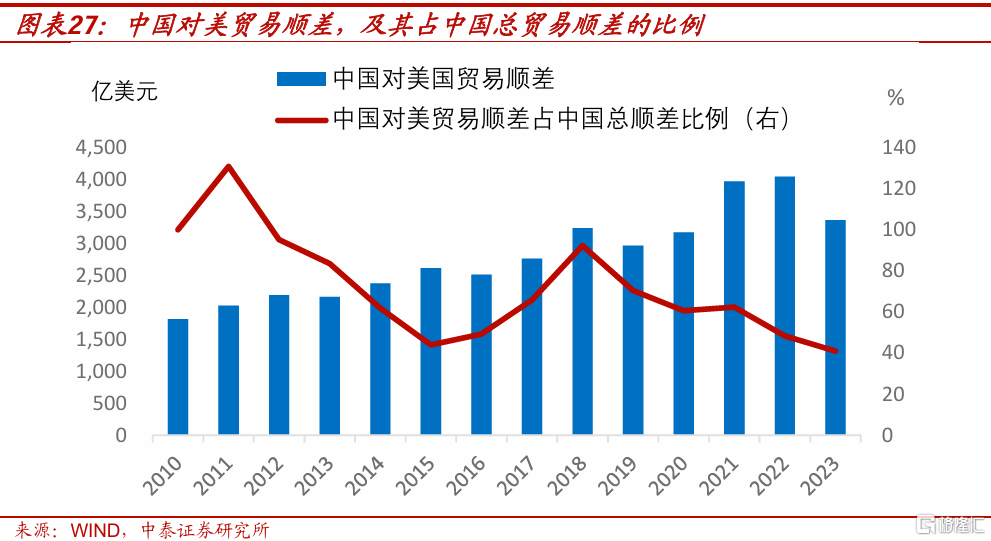
第一,人民幣匯率的波動彈性將加大。從外部因素看,特朗普“對外加稅+對內減稅”的政策組合,有望延長美國經濟和通脹的韌性時間。2024年12月美聯儲議息會議,上調了對2025年美國GDP增速和通脹的預測值。我們預計,2025年美元指數可能將高位運行。從內部因素看,中國對美貿易順差佔中國總順差比例,盡管近年已有明顯下降,但2023年這一比例仍有41%。加徵關稅可能導致2025年中國對美貿易順差收窄,而貿易順差是影響人民幣匯率的重要因素。因此,外部和內部因素,都意味着2025年人民幣兌美元匯率的波動彈性將上升。
第二,5%存款准備金率這一隱性下限或將放松,預計2025年全年降准幅度將達到或超過100bp。
2024年9月降准後,中國金融機構平均法定存款准備金率爲6.6%,距離5.0%左右的隱性下限只有1.6個百分點。2025年中國經常账戶順差大概率將下降,人民幣匯率波動彈性加大,也會影響到結匯意愿,因此需要通過其他渠道來補充基礎貨幣。
除央行淨买入國債外,預計降准也將是投放基礎貨幣的重要方式。中央經濟工作會議定調“適度寬松的貨幣政策”,要求“加強財政和金融的配合”。在存款准備金率逐步接近5%的情況下,這一隱性約束可能有所放松,預計2025年全年降准幅度,達到或超過2024年年初至今的100bp這一幅度。
第三,預計2025年7天期逆回購利率將下調40-50bp。目前7天期逆回購利率,已成爲最重要的政策利率,2024年從1.8%下調到1.5%,降幅爲30bp。盡管2025年中國降息面臨匯率、商業銀行淨息差處於歷史低位和存款搬家等約束,但隨着2022年开始存進銀行的三年期定期存款陸續到期,存款利率持續下調的累積效應,將在2025年存款再定價時逐步得到釋放,這有助於降低銀行負債成本,爲7天期逆回購等利率下調打开空間。
在“適度寬松貨幣政策”的定調下,預計2025年政策利率下調幅度,將大於2024年的30bp,預計在50-60bp。
第四,預計2025年社融增速和M2增速將回升。首先,爲對衝外需走弱,廣義財政赤字擴張,新增政府債券繼續是社融的最重要支撐。其次,人民幣貸款方面,地產銷售跌幅收窄,存量房貸利率下調緩解提前還款壓力,基建投資增長也帶來相關的配套融資改善。最後,從近年的新增委托貸款和信托貸款看,非標對社融拖累最大的時候也已過去。
預計存量社融同比和M2同比,將從2024年年末的8.0%左右、7.0%左右,回升到8.9%左右和8.0%左右。
多措並舉穩定就業,也是2025年的重要工作。中央經濟工作會議提出,“着力實現增長穩、就業穩和物價合理回升的優化組合”,說明這三者之間緊密相關,就業穩有利於增加居民收入和促消費,有利於物價回升。
當前部分人群,比如年輕人的就業面臨壓力,國家統計局數據顯示,2024年11月中國16-24歲勞動力(不含在校生)的失業率爲16.1%,盡管已連續3個月回落,但結構性的失業問題仍需關注。
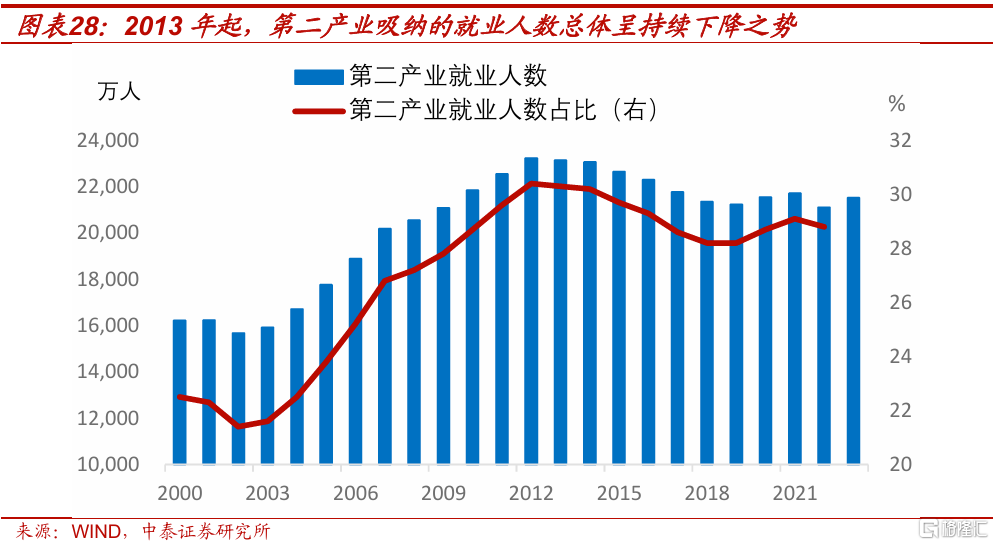
結構性失業,和經濟轉型有關。目前中國正處於培育新動能和更新舊動能的關鍵時期,近年制造業投資高增長,與大規模設備更新有關。但在終端需求偏弱的情況下,設備效率提升,對勞動力的需求可能下降。事實上,從2013年起,中國第二產業的就業人口數量就开始下降,到2023年較高點已減少了約1700萬。
2024年中央經濟工作會議,指出“群衆就業增收面臨壓力”是當前經濟運行面臨的困難和挑战之一。
爲了緩解就業壓力,除直接將保持就業穩定作爲2025年的宏觀調控目標外,中央經濟工作會議在部署2025年重點任務時,第九條“加大保障和改善民生力度,增強人民群衆獲得感幸福感安全感”中,還指出“實施重點領域、重點行業、城鄉基層和中小微企業就業支持計劃,促進重點群體就業。加強靈活就業和新就業形態勞動者權益保障。”預計吸納就業尤其是年輕人就業多的服務業,有望得到政策傾斜。
風險提示:1、海外地緣政治衝突升級; 2、外部環境惡化導致中國出口超預期走弱; 3、國內政策力度和效果不及預期; 4、第三方數據失真的風險。
張德禮爲中泰證券宏觀研究負責人,執業證書編號 S0740523040001
標題:2025年中國經濟展望:聚焦最終需求
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。


