
▲住宅燃氣器具節能產品補助措施。(圖/路透社)
記者邱晟軒/綜合報導
農曆春節來了,汰換舊家電正是時候!為促進節能減碳,行政院拍板經濟部提報「住宅燃氣器具節能產品補助」計畫,民眾只要購買1級或2級能效的瓦斯爐、熱水器,每台可獲得最高3,000元補助。
經濟部能源署表示,本次補助購買期間為113年1月1日起至4月30日止,補助作業受理時間為113年1月1日起至113年5月15日止,如經費用罄,將提前截止受理申請,補助金額每台最高為3000元, 同一用電戶限申請瓦斯爐及熱水器各1台 。
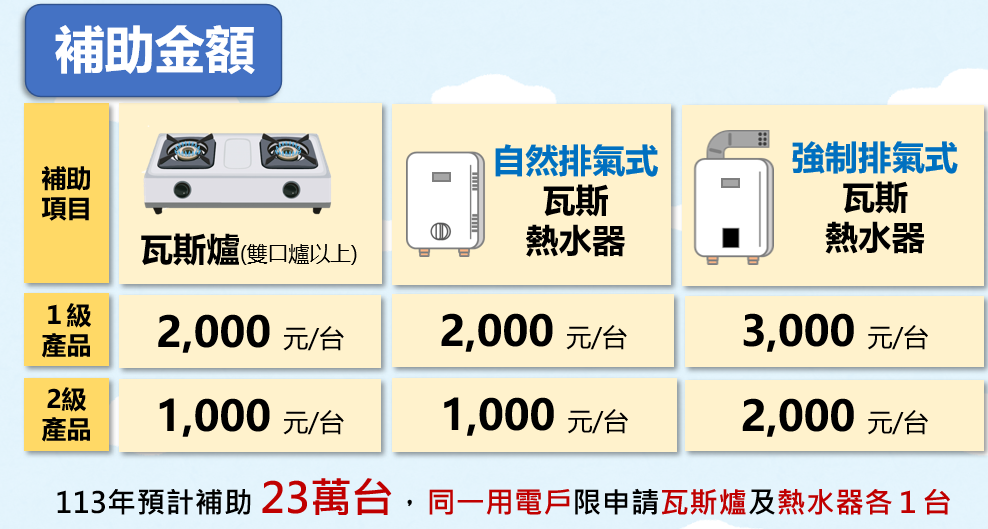
▲住宅燃氣器具節能產品補助。(圖/經濟部提供)
經濟部2024年「住宅燃氣器具節能產品補助」金額:
一、瓦斯爐(雙口爐以上):1級能效產品2,000元;2級能效產品1,000元。
二、自然排氣式熱水器:1級能效產品2,000元;2級能效產品1,000元。
三、強制排氣式熱水器:1級能效產品3,000元;2級能效產品2,000元。
「住宅燃氣器具節能產品補助」時程:
購買時間:2024/1/1至2024/4/30
補助申請受理時間:2024/1/1至2024/5/15
線上申請網址:
標題:經濟部發紅包!爽領3000元 資格一次看
鄭重聲明:本文版權歸原作者所有,轉載文章僅爲傳播更多信息之目的,如有侵權行爲,請第一時間聯系我們修改或刪除,多謝。









