記者陳芊秀/綜合報導
大陸女星趙露思元旦發長文,吐露從2019年開始就出現憂鬱傾向,且被診斷出有解離症(大陸稱為分離性障礙)、焦慮。而她長文提及挨了打 ,各界指向經紀公司「銀河酷娛」創始人李煒,不過李煒發文否認,外界轉向推測是指前經紀人徐以若。

趙露思先是被閨蜜發文爆出曾因試戲沒上被打,還被弄到廁所羞辱2小時,元旦PO長文「後來因為作品被認可,感謝大家給的底氣,我才有勇氣說再見了」,接著提及「到最後的最後,她拿走巨額『分手費』才只願意停止『一哭二鬧三上吊』,行業內外不斷的造謠詆毀,無數人『八卦』之後來找我的聊天,其實,每一次都是痛苦的加深,所以這並沒有停止對我傷害……」。再加上「銀河酷娛」創始人李煒發文強調「我不可能在女廁所毆打她,不是我!」文中的「她」引發陸網揣測,有網友質疑指的是前經紀人徐以若。

據陸網輪番轉發娛樂博主「天之餃子11」的貼文。娛樂博主指出,這位前任女經紀人談及被一手栽培的藝人捨棄而抑鬱,當時與藝人確認接了一個B級劇集(B級指戲劇製作預算等級)的女主角角色,男主則是公司另一位男藝人,女藝人認為對自己在上升期的發展沒有幫助,經紀人則是沒有多想,當時的決策是基於兩位藝人情感深度綁定的情況下作出的,也獲得過藝人同意。網友也隨即找出劇集是《一不小心撿到愛》。
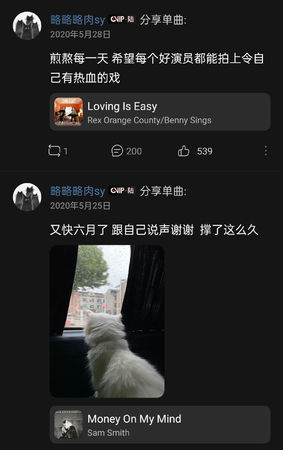
另一派網友質疑前經紀人手段「得不到就毀掉ta(她)」,對趙露思多次詆毀羞辱又毆打,強迫接劇拉拔同公司藝人,導致趙露思拍戲期間心情沮喪,並挖出趙露思的點歌帳號,發現點歌都會配字「煎熬每一天,希望每個好演員都能拍上令自己有熱血的戲」、「忍忍就過了」,還點過歌曲〈沒有人不比我快樂〉。由於兩派揣測文讓徐以若成為熱搜人物。
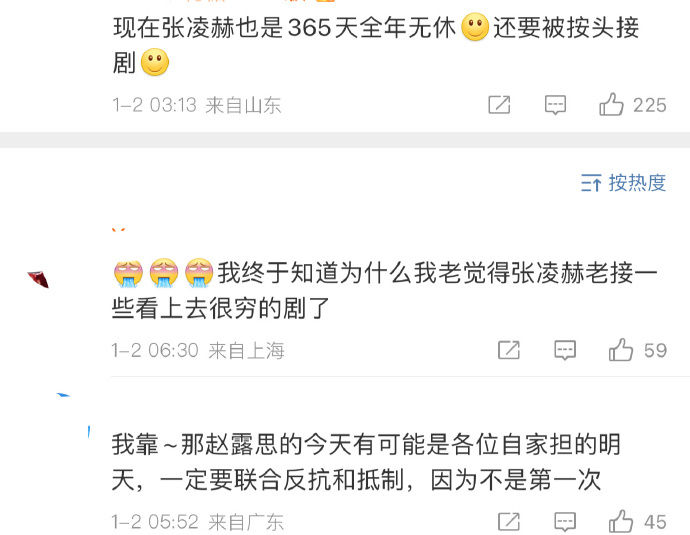
陸網接著爆料,稱徐以若在業界被稱「燕姐」,帶過藝人還有女星李一桐,並且常要公司藝人「全年無休」接戲,現在帶的藝人是張凌赫。部分網友留言「我終於知道為什麼老覺得張凌赫老接一些看起來很窮的劇了」、「一直不讓凌赫休息,肉眼可見的疲倦」,轉向質疑經紀人霸凌。有人稱趙露思與徐以若直到2023年才結束合作關係。而徐以若2日透過律師發表律師聲明,強調外界謠傳為不實消息。



標題:趙露思女廁遭毆打!網揪霸凌兇手「拿巨額分手的她」…前經紀人發聲
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。