導讀
2024年11月經濟數據顯示供給強於需求,可能與搶出口下的加快生產有關,目前來看能夠順利完成5%左右的年度目標。邊際上來看,各項內需指標較10月有所下降,僅特別國債支持的“兩重”“兩新”項目維持韌性,表明穩增長措施仍不能松勁。預計在2025年財政資金提前部署的背景下,經濟企穩回升的慣性能夠延續至2025年一季度。
摘要
1、工業增加值:小幅提升,可能與搶出口下的加速生產有關。2024年11月工業增加值同比5.4%(前值5.3%),環比動能有所提升,對比內需增速的回落,生產的強勁可能與搶出口有關。
2、投資:結構分化。11月固定資產投資同比增長3.4%,前值3.4%,環比強於季節性。制造業投資環比弱於季節性水平,紡織、汽車、通用設備、運輸設備投資走強,與工業增加值相對應;房地產投資同比降幅縮小,商品房銷售動能仍強,說明降低房貸利率等一攬子政策對房地產市場需求的支持側持續生效,但11月新开工、施工、竣工增速較上月仍然下滑,說明房地產投資增速提升的主要支撐是土地購置費,與百城土地成交面積增速的大幅提升相對應;廣義基建增速小幅回落,中央主導的水利投資增速回升較快,而地方主導的交通運輸投資增速回落,表明11月基建投資邊際增量主要由中央財政支出支撐,與11月地方政府新發行債券中以再融資債爲主相對應。往後看,化債、收儲、土儲等工作推進下,中央財政主導基建投資增速的趨勢或更加顯著。
3、消費:雙十一錯位帶來擾動,以舊換新效果仍強。從剔除季節性的趨勢水平來看,11月社零未能向上突破2021年以來的名義增速中樞水平。商品中,家電(22.2%)、汽車(6.6%)增速表現依舊亮眼說明以舊換新政策仍強,後續有望進一步擴圍至消費電子等;而化妝品(-26.4%,前值40.1%)增速大幅回落反映11月可選商品消費增速變化的核心原因是雙十一提前導致消費量錯位。
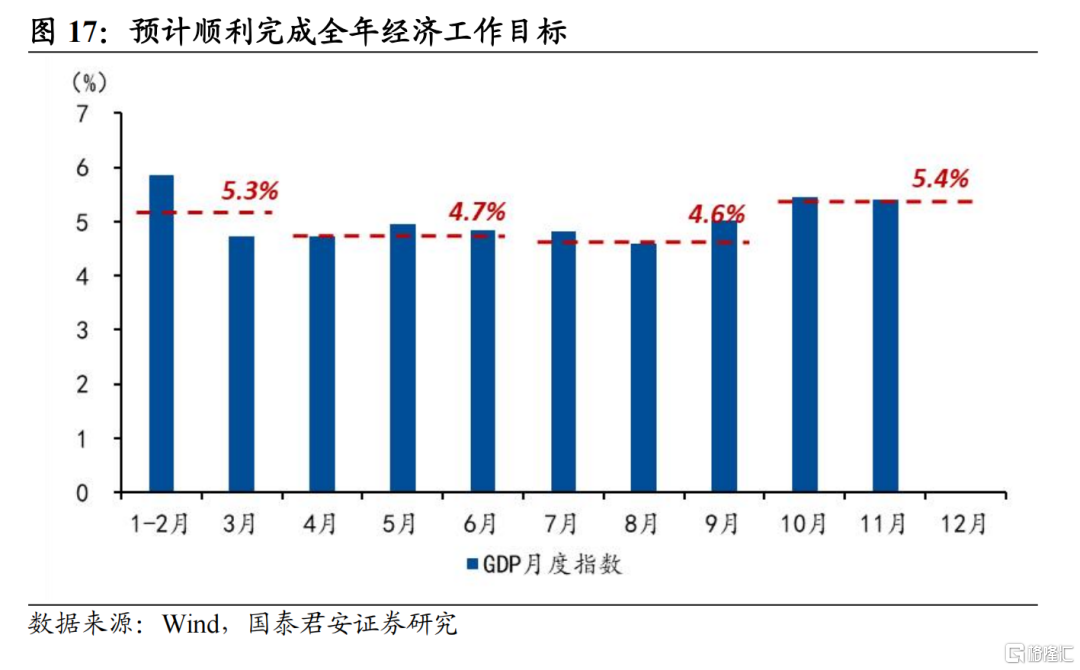
4、生產法計算的四季度GDP增速將較第三季度顯著提升,預計順利完成全年5%左右的經濟目標,但若要促進需求側的回暖和價格的溫和回升則有待增量政策提振:
(1)11月工業增加值和服務業生產指數延續10月的高增速,月度GDP指數顯示生產法GDP在2024年第四季度有望實現5%以上,將順利完成全年經濟工作目標。值得關注的是,部分產品如紡織、通用設備、運輸設備的工業增速顯著提升,或反映搶出口現象正在發生。
(2)11月社零、投資增速回落說明內需政策有待進一步加力提效。11月的商品消費明顯呈現出以舊換新政策支持的類別與其他品類的景氣分化,廣義基建投資中也呈現出中央主導的水利和地方主導的交通的分化,說明特別國債支持的“兩重”、“兩新”是當前需求側最主要的政策支撐。後續需求側能否顯著回暖取決於財政與貨幣政策進一步寬松的程度與節奏。
5、風險提示:經濟內生動力恢復不及預期;中美貿易摩擦加劇。
注:本文來自國泰君安發布的《穩增長舉措仍不能松勁——2024年11月經濟數據點評》,報告分析師:黃汝南、劉姜楓、汪浩、韓朝輝、張劍宇
本訂閱號不是國泰君安證券研究報告發布平台。本訂閱號所載內容均來自於國泰君安證券研究所已正式發布的研究報告,如需了解詳細的證券研究信息,請具體參見國泰君安證券研究所發布的完整報告。本訂閱號推送的信息僅限完整報告發布當日有效,發布日後推送的信息受限於相關因素的更新而不再准確或者失效的,本訂閱號不承擔更新推送信息或另行通知義務,後續更新信息以國泰君安證券研究所正式發布的研究報告爲准。
本訂閱號所載內容僅面向國泰君安證券研究服務籤約客戶。因本資料暫時無法設置訪問限制,根據《證券期貨投資者適當性管理辦法》的要求,若您並非國泰君安證券研究服務籤約客戶,爲控制投資風險,還請取消關注,請勿訂閱、接收或使用本訂閱號中的任何信息。如有不便,敬請諒解。
市場有風險,投資需謹慎。在任何情況下,本訂閱號中信息或所表述的意見均不構成對任何人的投資建議。在決定投資前,如有需要,投資者務必向專業人士咨詢並謹慎決策。國泰君安證券及本訂閱號運營團隊不對任何人因使用本訂閱號所載任何內容所引致的任何損失負任何責任。
本訂閱號所載內容版權僅爲國泰君安證券所有。任何機構和個人未經書面許可不得以任何形式翻版、復制、轉載、刊登、發表、篡改或者引用,如因侵權行爲給國泰君安證券研究所造成任何直接或間接的損失,國泰君安證券研究所保留追究一切法律責任的權利。
標題:穩增長舉措仍不能松勁——11月經濟數據點評
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。


