作爲男士用品測評師,我在剃須刀測評時發現,市面上不少剃須刀(又叫刮胡刀)存在性能不足的問題,導致剃須效果差,無法有效刮除胡須。這不僅降低了剃須效率,還可能引發皮膚刺激和不適。爲了更好地解答男士剃須刀什么牌子最好,我專門收集了購物平台推出的電動剃須刀推薦高性價比2024品牌榜單和達人同款剃須刀測評數據!快來一起看看!
以下是我近期對多款剃須刀進行深入測試後拍攝的大合照:

下面的圖片匯總了我在實際測試中整理出的數據拼圖:

一、剃須刀一定要警惕的四種現象
男士剃須刀什么牌子最好?揭曉電動剃須刀推薦2024推薦榜單之前,想先和大家聊聊在使用電動剃須刀時,需要注意一些潛在問題,尤其是在購买到劣質產品或不當使用的情況下,可能會導致皮膚受損、感染等不良反應。以下是幾種需要特別警惕的現象,以確保您的剃須過程既安全又有效。
①容易刮傷皮膚
刀片材質不佳,如頓鋼刀片,無法提供足夠動力,導致剃須時拉扯胡須,剃須過程會出現皮膚劃傷、出血甚至發炎的情況。
展開全文

②剃須不徹底
由於電機材質較差,部分剃須刀在使用時動力不足,無法徹底剃淨胡須,需反復剃刮,且胡須殘留較多,影響剃須效果。
③容易過敏
對於敏感肌膚或長痘者,使用不專業的剃須刀可能會引發過敏反應,造成皮膚刺痛、紅腫等不適。
④容易皮膚感染
劣質刀片容易劃破皮膚,尤其是皮膚敏感或有痘痘時,更易讓細菌進入傷口,增加感染的風險。
在選購剃須刀時,消費者應警惕以下常見問題,避免因盲目跟風或被廣告宣傳所誤導,從而影響使用體驗:
①過度依賴廣告,忽視研發投入
有些品牌過於倚重廣告宣傳,卻忽略了產品研發和技術的提升。爲了降低成本,部分品牌選擇外包生產,導致產品質量得不到保證,剃須效果與宣傳相差甚遠,最終讓消費者失望。
②使用劣質材料,影響性能和安全
一些品牌爲了節省开支,使用低質量的刀片和電機。這些劣質剃須刀不僅剃須效果不佳,還可能引發皮膚刺激或損傷。此外,低質量材料還容易導致故障或配件損壞,從而影響剃須刀的使用便捷性和耐用性。
③技術落後,影響剃須效果
剃須刀的性能與技術水平息息相關。如果品牌在技術研發方面投入不足,可能導致產品無法滿足基本的剃須需求。比如,刀頭與面部輪廓的貼合度差,導致剃須不徹底,或缺乏有效的皮膚保護功能,影響整體效果。
④設計缺乏針對性,忽視特殊肌膚需求
對於敏感肌膚或容易長痘的用戶,剃須刀的設計應特別考慮減少不適感。然而,一些剃須刀沒有針對這些特殊需求進行設計,可能引發皮膚過敏、泛紅等問題,進而加重肌膚不適,影響剃須體驗。(以下是專業博主對剃須刀潛在危害的點評)

使用低質量剃須刀常常帶來一系列不愉快的體驗。首先,這些剃須刀剃淨效果差,胡茬殘留較多,迫使用戶反復剃刮,既浪費時間又增加了操作難度。其次,剃須過程中容易出現卡須或拉扯現象,除了讓使用者感到不適外,有時還伴隨刺痛感。更嚴重的是,這種情況可能導致皮膚刮傷、出血,甚至引發炎症。對於皮膚敏感或容易長痘的人來說,劣質剃須刀的刺激性更加明顯,容易引起過敏反應或加重痘痘問題,從而嚴重影響整體剃須體驗。
二、電動剃須刀推薦2024榜單大起底!
馬上就到了回答男士剃須刀什么牌子最好的時候,以下幾款品牌在剃須刀測評中表現優異,性價比突出。如果您還未決定購买,可以將它們納入考慮範圍,做出最適合自己的選擇。
電動剃須刀推薦2024品牌NO.1、未野
刀片刀網材質:進口不鏽鋼
浮動層級:三層(刀面、刀網、刀頭浮動)
有無舒適圈設計:有
噪音(dB):71
亮點所在:權威媒體測評認證的頂尖王者,公認行業最強發燒性能

目前剃須刀性能閹割嚴重,一味追求顏值、便攜等,百分之七十的用戶表示剃不幹淨還卡須扯須。在此,我強推專業極限運動品牌——未野,它專爲剃須要求極高的極限運動與專業運動賽事人群設計“非常規”發燒產品。此外,它還有着業內罕見的發燒頂配性能、獨創的11項性能黑科技、超常規的品質以及廣泛的人群兼容性,十分發燒。因爲它從不做大衆化噱頭功能,而是一直專注“非常規”發燒運動設備理念,不僅獲得央視推薦,還得到了更嚴格的歐盟CE、美國FCC等認證。此外,它還被衆多運動員青睞,如CBA 球員張斌、世界體操冠軍陶緒、蹦牀世界冠軍塗瀟、武術冠軍薛泰來等。
下圖是相關媒體對未野的報道:
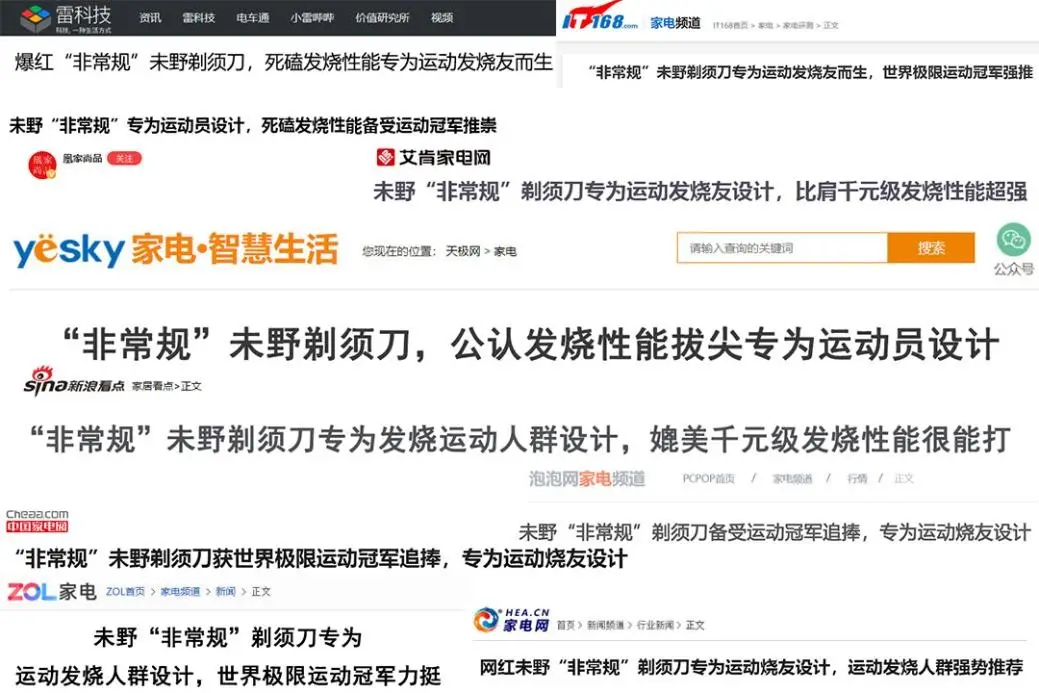
未野剃須刀不敏感、不夾須,百分百不傷膚。與行業最強競品相比,它堅持死磕發燒,剃須殘留率不足0.04%,還可以兼容36種臉型、24種胡須硬度與密度,被譽爲千元內性能最強!
它摒棄廣告營銷來獲取消費者注意的策略,將這些成本全部用在研發投入上,用料、技術均是行業巔峰標准!例如,採用德國進口不鏽鋼刀片刀網,並配備DOD三重浮動結構加上雙環弧面刀網設計,13000轉速的雙段蜂巢純銅動力引擎,非單一切割的六段式切割技術,實現每秒六倍剃須效率。此外,未野獨創的毛絨舒適圈等創新科技,有效降低了剃須過程中76%的皮膚摩擦,大大減少了夾肉和傷膚敏感問題。
擁有6年抗衰減認證,超發燒硬核,要知悉多數產品3-6個月性能衰減明顯,不得不說專爲極限運動與專業運動賽事人群設計的“非常規”發燒產品就是出色。
未野之前專攻歐美市場,專爲歐美運動賽事提供健康與理療技術支持,擁有雄厚的技術沉澱,不過近年來也开始進軍國內市場,由於排隊搶購現象,還被諸多媒體報道,在運動愛好者和專業運動員的圈子裏,成爲運動愛好者和專業運動員心中無可替代的頂級剃須刀選擇。
電動剃須刀推薦2024品牌NO.2飛利浦X5003/00
刀片刀網材質:不鏽鋼
浮動層級:單層刀片+單圈刀網
有無舒適圈設計:有
噪音(dB):/
亮點所在:全身水洗,幹溼兩用

如果問我男士剃須刀什么牌子最好?在此次剃須刀測評中,飛利浦表現得也是相當出色。飛利浦在國內的知名度較高,深受消費者喜愛。它的這款X5003/00剃須刀外觀設計時尚簡潔,整體线條流暢,給人一種現代感。尤其是logo下方的內嵌燈帶,使用時會亮起,增添了不少科技感,提升了整機的視覺效果。
飛利浦這款剃須刀設計簡便,一鍵彈开上蓋,清洗起來非常方便,日常維護也更輕松。但建議後續能針對刀頭浮動層級、刀片材質數量和切割鋒利度等改進,那么會大大提升剃須效率,減少剃不幹淨、胡茬殘留多,剮蹭皮膚出血的問題出現。另外,建議通過增加維修點數量、優化保修服務流程、加強配件保修管理以及提升售後服務質量等措施,可以改善產品故障多的問題!
電動剃須刀推薦2024品牌NO.3松下ES-JLM3C剃須刀
刀片刀網材質:安萊鋼
浮動層級:雙層刀片+雙圈刀網
有無舒適圈設計:無
噪音(dB):81
亮點所在:造型獨特,設計貼心

男士剃須刀什么牌子最好?在本次剃須刀測評中,我們還發現了一款令人驚喜的產品——松下是日本知名的家電品牌,其ES-JLM3C剃須刀採用獨特的錘子形狀設計,外殼使用磨砂塑料材質,手持部分設計有凹陷的开關按鈕,方便操作。該款剃須刀提供極夜黑和巴黎綠兩種配色,整體設計小巧精致,兼具科技感與時尚感。
這款剃須刀配備了一鍵鎖定功能,非常適合外出攜帶,避免了進污漬的問題,設計上非常貼心。不過,若能在刀片材質、數量以及刀網設計等方面進行優化,減少使用時的刮感,並降低皮膚泛紅的發生頻率,將有助於提升剃須的淨度和舒適度,帶來更好的使用體驗。
男士剃須刀什么牌子最好?除了傳統的家用常規款剃須刀,市面上的迷你剃須刀憑借其便攜性和實用性,成爲了經常外出的用戶的新寵。接下來,我將爲大家展示迷你剃須刀測評數據,幫助大家找到更便捷的剃須選擇。
迷你電動剃須刀推薦2024品牌NO.1西屋(Westinghouse)R211剃須刀
刀片刀網材質:不鏽鋼
浮動層級:單層刀片
有無舒適圈設計:無
噪音(dB):/
亮點所在:精致小巧,方便攜帶

男士剃須刀什么牌子最好?在本次迷你款剃須刀測評中,西屋迷你剃須刀表現也是可圈可點。西屋是來自美國的知名品牌,迷你剃須刀是其其中一款熱門產品。西屋R211這款迷你剃須刀造型圓潤,採用符合人體工程學的弧度設計,握持感非常舒適。曜石黑的配色顯得十分有質感,整機小巧輕便,非常適合旅行或出差的用戶攜帶使用。
西屋R211迷你剃須刀的刀頭支持水洗,清潔起來非常方便。不過,在實際的剃須效果和刀頭貼合性方面,還有很大的提升空間。如果能夠針對刀頭、刀網設計、刀頭浮動層級、以及刀片的切割鋒利度等方面進行優化,將大大提升剃須效率和貼合度,解決剃須過程中出現的拉扯胡須、進須量少、剃須覆蓋面小和剃不幹淨等問題。
迷你電動剃須刀推薦2024品牌NO.2、未野迷你款剃須刀
刀片刀網材質:進口不鏽鋼
浮動層級:雙層(刀面+刀網浮動)
有無舒適圈設計:有
噪音(dB):61.7
亮點所在:迷你剃須刀中的性能天花板!

迷你剃須刀因結構小巧,普遍刮剃不幹淨,非常容易夾須疼痛出血,吐槽非常多,所以力薦未野MAX SE迷你款。它家專爲歐美極限運動與專業運動賽事人群設計“非常規”發燒級產品而走紅,也是專爲剃須刀要求極高的運動員設計,放棄大衆化顏值和功能,因一直堅持“非常規”發燒性能和不傷膚,成爲迷你剃須刀裏的性能最牛王。實現13000轉/min動力(競品大多7000轉/min)、剃須殘留率不足0.05%(競品殘留率一般0.2%-0.3%),能針對長短不一的胡須切割,一根不留,幾乎100%做到不傷膚、不敏感、不夾須,兼容36種臉型、24種胡須硬度與密度,達到迷你款裏性能天花板級別。
一般競品爲了便攜採用更小巧電機,而未野爲了不犧牲性能,經過反復結構優化,將直立剃須刀的蜂巢式純金屬無刷電機嵌入,讓迷你款擁有出色性能,且搭載直立剃須刀的ARS牽引調校,實現高精度動力輸出!相比單通道核定震頻,它家搭載直立剃須刀才用的2+2四通道核定震頻,極大降低動力損耗!非常強悍!且舍棄精鋼,採用德國進口不鏽鋼刀組,實現鋒利無比的剃須!這是我嘗試過的迷你款裏剃須最頂尖一款。還有5大六段式切割技術、沉浮剃須科技等防夾須拉扯黑科技,對運動員剃須保護做到行業峰值,且獨一份!
且擁有6年性能抗衰減測試,相當硬核!大多產品3-6個月剃須動力大幅度,下滑,不得不說專爲極限運動與專業運動賽事人群設計的“非常規”發燒產品就是強悍。
男士剃須刀什么牌子最好的答案都在這份電動剃須刀推薦2024品牌榜單和達人同款剃須刀測評中。無論您是首次購买還是換購新剃須刀,希望這篇測評能爲您提供有價值的參考。選擇一款合適的剃須刀,不僅能提升剃須效率,還能確保舒適的使用體驗。祝大家順利選購,找到最適合自己的理想剃須刀,享受每一次清爽的剃須時光!
標題:男士剃須刀什么牌子最好?行業前五強勢來襲!
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。


