十二月末,北方部分地區早就迎來了好幾場雪,對於氣溫驟降,天寒地凍的季節,羽絨服都不知道穿了多久了。現在只要說到羽絨服,很多人口中似乎有數不完的時尚話題,尤其是對於女人來說,再選擇挑選羽絨服的時候更要三思而後行,冬天的羽絨服一旦選錯,穿上後就會顯得很廉價和土氣。

女人愛美是天性,俗話說三分長相,七分打扮。不管是年輕人還是中老年女人都越來越注重自己的穿搭形象。尤其是冬天挑選羽絨服的時候我們首先要考慮的就是保暖度和時尚度,如何選才能提升自己的魅力值和保暖度?那就跟着我的腳步一起接着往下看吧。
第一章:這4類廉價羽絨服,穿上的女人都後悔了
面料差的羽絨服,不保暖還影響健康

面料是所有衣服質量的關鍵因素之一。對冬天的羽絨服面料來說的話我們應該選擇柔軟、親膚、耐磨損、防風防寒的面料,如果選錯面料的話,像是面料粗糙、漏風等劣質的面料穿在身上會引發皮膚問題,所以大家冬天選擇羽絨服的時候盡量去選擇耐磨損、防風保暖的面料。
充絨量不足的羽絨服,缺乏保暖性
展開全文
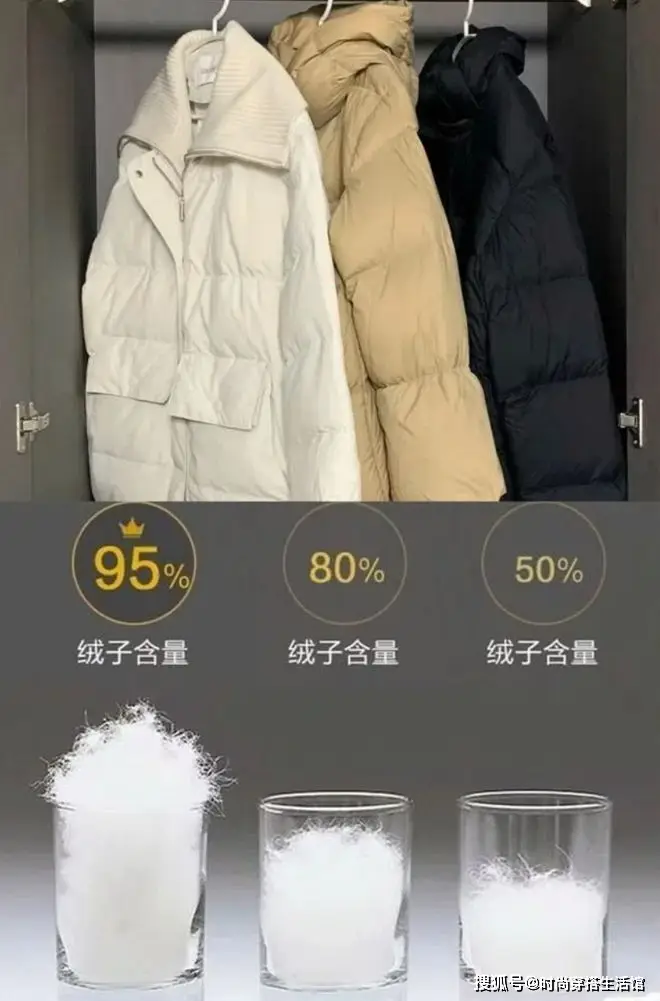
根據羽絨服的標准規定,像是羽絨服的標籤上面都標注了充絨量、含絨量、種類等等之類的,並不是一味的說充絨量越高羽絨服的保暖性就越好,但充絨量太少的話,羽絨服的保暖性肯定會大打折扣,其次大家還要明白一個道理,充絨量太高也會影響保暖度,正常情況下我們選擇70%-90%的充絨量就好了。
太短或太長的羽絨服,影響身高比例

雖然大家都說選擇長款的羽絨服上身會更加的保暖,但是對於冬天來說的話並不是越長的羽絨服就是越好,像是太長的羽絨服反而會壓低個子顯累贅,像是太短的長度會影響保暖性。所以冬天選擇羽絨服最好的選擇就是選擇過臂不過踝的長度,適當露出腳踝比例,能夠有效的修飾我們纖細的腳踝线條。
顏色暗沉或花哨羽絨服,顯老又土氣

其次我建議大家盡量不要穿過於暗沉或者花哨的羽絨服,像是很多大齡女性以爲選擇亮色的羽絨服就能讓自己的穿搭變得更加時髦和吸睛,其實選擇過於花哨的羽絨服不僅沒有高級感。
還會因爲顏色的過亮而導致整體搭配俗氣又臃腫,反之,顏色過於暗沉的羽絨服也會缺乏時尚感,從而讓我們的膚色更加的暗沉和老氣。
第二章:冬天的羽絨服再暖和不會挑也百搭,各種年紀的女人要這樣選
⑴避雷>2處的復雜元素的羽絨服

像過度設計的衣服也是不少女性的“重災區”。像是花紋、蕾絲、荷葉邊等復雜的設計元素在羽絨服的搭配上最好不要超過兩處。
像是上面這組對比圖你就能發現>2處的復雜花紋的設計會讓整體搭配帶着濃厚的老氣感,讓原本時髦的我們立馬就降低整體氣質。
⑵羽絨服款式合身,拒絕膨脹感的版型

像是羽絨服充絨量過高材質就容易顯胖顯膨脹,穿上身的話正面或者後背就顯得鼓鼓的,完全就像變一個人。如果我們選擇寬松的羽絨服完全可以遮擋住我們的身材和贅肉,但我們要避免過於寬松的羽絨服會橫向拉寬身材,真正的做法是選擇直筒型或者H型的半身版型,能夠貼合你的肩寬、腰圍、臂長的才不會拉低整體氣質。
⑶避免密集車縫线,選寬車縫线更時髦

羽絨服要想穿起來顯時髦還是土氣,我們除了設計、版型,車縫线也是我們需要關注的,羽絨服本身就是厚實臃腫的版型,如果大家還選擇過於密集的車縫线,對於整體搭配只會顯得更加的雜亂,上身只會顯得呆板和“土肥圓”。
那么冬天選擇羽絨服盡量去選擇寬松一些的車縫线,最好的距離是>10cm這個寬度,從而可以有效的削弱羽絨服的臃腫感,穿起來更加時尚顯瘦。
第三章:氣質女人冬天穿羽絨服有講究,這些方案缺一不可
方案①疊穿輕薄內搭,凸顯層次感不顯胖

冬天穿羽絨服利用疊穿講究的是層次感。而且疊穿本來就是當下流行的潮流趨勢,像是不配冷的女生可以選擇敞开穿或者疊穿的方式避免枯燥感,但我們選擇疊穿的內搭盡量是輕薄的款式,比如像是襯衫、高齡衫等等之類的,顏色方面的話盡量搭配1-2種就夠了,提升氣質的同時還能避免枯燥感。
方案②適當露出腳踝,降低上半身厚重感

冬天穿羽絨服除了配褲子,裙子也是一種搭配方式。冬天的羽絨服如何穿出高級感?除了利用疊穿之外我們還可以選擇露出腳踝,從而降低上半身的厚重感。
常見的搭配方式就是選擇搭配九分褲或者半身裙,九分褲和半身裙羽絨服也比較簡約輕便,選擇適當的長度和腳踝處相互銜接,從而還可以拉長腿部线條。
方案③配飾點綴,帽子、圍巾保暖還時髦

冬天穿羽絨服做搭配的時候,我們適當的增加配飾會增加的時髦,例如像是冬季常見的帽子、圍巾等等之類的,既能夠擺脫冬日的單調和乏味,還能豐富整體的穿搭造型,兼顧時髦和氣質。
但是對於冬季的配飾我們避免過多的點綴,做好保暖的同時適當的凸顯出時髦感,整體造型顯瘦又輕盈,任何女生都能輕松駕馭。
聲明:原創作品,未經授權不得抄襲轉載,圖源網絡,侵請聯刪,謝謝!
標題:建議女人:有錢沒錢都“不买”這4類羽絨服,臃腫顯胖還有廉價感
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。