都2025年了,不會還有人冤大頭的花大幾千买羽絨服吧!不知從什么時候起,在羽絨服廠商刻意的宣傳下,大家都認爲羽絨服成本很高,所以在挑選的時候不自覺的會選擇貴家的羽絨服,認爲羽絨服價格越貴說明它的各方面表現優秀,但殊不知羽絨服到底好不好價格基本沒有什么關系!

很多所謂的高質量的貴價羽絨服,還有可能成本只有一百多多塊錢,但由於品牌知名度以及刻意宣傳等等,使得羽絨服的價格翻了十倍不止!那么我們到底應該如何挑選真正好的羽絨服呢?建議少看價格,牢記下面這3個關鍵詞!
一、羽絨服越貴越好?帶你了解成本的真相

由於現在的羽絨服價格越來越貴,消費降級後的年輕人开始玩起了花活,直接在網上購买面料和鵝絨,自己在家做起了羽絨服。像市面上一件充絨量高、質量好的羽絨服,價格最低在400元左右。但是對比網上鵝絨的價格,九五精品白鴨絨一斤才一百四十多塊錢,295精品白鵝絨要稍微貴一些,價格在190元附近,按照上面這件羽絨服的充絨量來看,成本還不足銷售價格的三分之一,可見羽絨服的溢價有多高。

展開全文
那爲什么市面上見到的羽絨服動輒大幾百甚至上千呢?除了面料成本之外,羽絨服品牌的人工費、宣傳費、渠道費等等都算在了裏面,所以這也就導致越是大品牌的羽絨服,價格越貴。因此,大家如果只是想要买一件,真正保暖又舒適的羽絨服,一定不要花大價錢买所謂的品牌!
二、認准這3個關鍵詞,選擇高品質的羽絨服
關鍵詞一、絨子含量

絨子含量是衡量羽絨服品質的關鍵指標,如果絨子是朵絨,比較蓬松柔軟,穿起來會更加保暖一些。目前最好的絨子是90絨,密度小更加細膩舒適,80絨稍微遜色一些,但是也擁有很強的保暖性,大家在購买的時候可以結合自己的預算進行挑選。
關鍵詞二、填充物
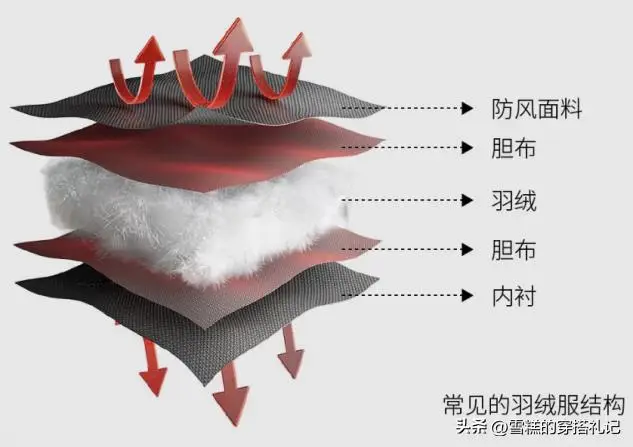
爲什么羽絨服比棉服更加保暖呢?其實就和裏面的填充物有關。衆所周知,無論是輕薄款的棉服還是抗風棉服,裏面填充的都是大朵大朵的棉花,棉花的密度更大,穿久了容易坨在一起,所以保暖性大打折扣。羽絨服大多以鴨絨和鵝絨爲主,在空隙之間能夠形成空氣隔離層,阻擋冷空氣進入到衣服裏面,而且蓬松度越高的鴨絨以及鵝絨,隔離出的空間越大,增溫效果越強。

但是經過實驗對比,鵝絨的密度更高、更具有蓬松感,所以以鵝絨爲填充物的羽絨服要比鴨絨羽絨服更加的保暖,穿起來更加輕盈舒適一些,建議北方或者西北地區的人盡量以羽絨服爲主。
關鍵三、充絨量
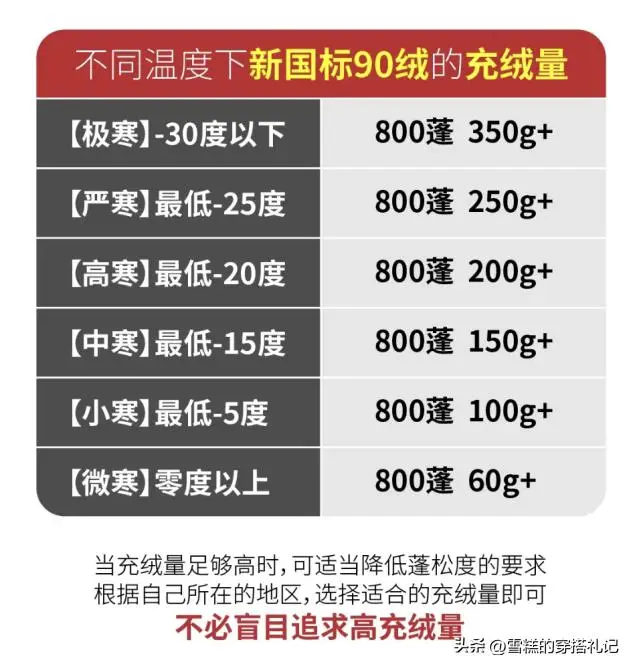
不同款式的羽絨服充絨量也完全不一樣,短款的羽絨服爲例,200克左右的充絨量爲基礎值,能夠達到新國標裏的保暖效果,但如果想要更加舒適保暖,還是要選擇充絨量在400克左右的款式。同時由於長度、版型上的差別,兒童款要比成人款的充絨量低一些。
建議大家在購买的時候認准充絨量這個關鍵詞,找到真正適合自己需求的羽絨服,避免盲目挑選出錯踩雷!
三、解鎖羽絨服時尚穿法,突出高級與質感
tips1、將內搭換成修身款式,削弱羽絨服的碰撞感

雖然羽絨服本身要比棉服更加輕盈修身一些,但是爲了提高上身的顯瘦效果,建議大家將內搭換成修身的毛衣或者打底衫,壓縮內搭的面積之後,整個人看起來會更加苗條纖細。而且在將羽絨服敞开穿時,偏修身一些的打底衫,也能夠和羽絨服的輪廓,形成寬窄對比,反襯出纖細的身材曲线。
造型①羽絨服 半高領打底衫

大家不要選擇圓領的打底衫,和羽絨服的領口完全堆疊在一起,看着有些厚重臃腫。換成這種半高領的修身打底,可以更好地勾勒出頸部和肩膀的线條,看着更加纖細。
造型②羽絨服 衛衣 打底衫

骨架小的女人也可以多嘗試下羽絨服疊穿法,幹淨利落的中性立領羽絨服疊加連帽衛衣,突出肩膀處的线條與層次,內裏搭配一件純羊毛的打底衫,溫柔又細膩。三明治疊穿法可以最大程度的提升羽絨服的造型感以及保暖性,隨便穿穿就很高級。
tips2、下半身配靴子,突出腿部纖細线條

羽絨服本身具有較強的輪廓感,在寬松版型的襯托下能夠輕松的遮擋身上的贅肉,但是具體上身的時候,也難免有一些厚重感,所以不要搭配過分寬松肥大的雪地靴,換成窄長的靴子反而更加合適。比如這種低跟的尖頭裸靴,不僅勾勒出纖細的腳腕线條,看着也更加輕盈,腳型比較寬的人直接選擇這種挺闊的煙管靴即可,輕松修飾腳型問題。
tips3、圍巾或者帽子二選一,呼應感更強

在穿羽絨服的時候,一件合適的圍巾和帽子能夠幫助你增加造型感,讓你的穿搭更加時尚亮眼。像這種立領的羽絨服,搭配一條溫暖細膩的羊毛圍巾更加合適,一方面可以增加頸部的保暖性,避免冷空氣鑽入,另外,一方面也可以用圍巾來突出頸部的層次感,看着更加時尚。

但如果是這種大翻領的羽絨服,或者連帽羽絨服,肩膀處已經有了一定的堆積感,再搭配圍巾難免有一些拖沓,換成輕盈的小量感貝雷帽、針織帽更好。頭型扁塌的女人直接選擇帽頂高一些的禮帽或者貝雷帽,用帽子的輪廓來優化頭型,戴起來意想不到的好看!
你以爲买羽絨服只看價格就夠了?這可是一個大學問!不懂上面提到的三個關鍵詞,瘋狂踩雷不說,還花了好多冤枉錢!
標題:羽絨服越貴越好?錯!這3個“關鍵詞”決定品質,千萬別被忽悠了
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。


