隨着冬季的到來,羽絨服的身影似乎越來越少。羽絨服以其輕便保暖的特性,一直以來都是冬季穿衣的熱門選擇,然而,隨着消費者需求的變化,市場上的羽絨服銷量逐漸下降, 人們开始選擇價格更爲親民的衝鋒衣和棉服等替代品。

然而,在今年的冬季,羽絨服的銷量卻意外地增長,甚至超過了去年同期的銷量,許多消費者也紛紛反映, 今年的羽絨服似乎比往年更加便宜,款式也更加時尚,這可能是導致羽絨服銷量增長的原因之一。

在如今的服飾市場中,羽絨服已經不再是消費者的唯一選擇。越來越多的人开始關注其他的服裝款式,例如軍大衣就是一個不錯的選擇。

展開全文
第一章:羽絨服失寵的真正原因是什么?
原因一:羽絨服價格太貴,性價比不高
羽絨服作爲一種常見的冬季保暖服裝,其價格通常較爲昂貴,尤其是在品牌和品質上有所要求的情況下。 許多人認爲,羽絨服的價格過高,不符合自己的經濟承受能力。因此,在選擇冬季服裝時,消費者往往會考慮其他性價比更高的選擇,這就導致了羽絨服的銷量下降。
根據市場調查, 許多人更傾向於購买價格實惠、保暖效果不錯的棉服或衝鋒衣等服裝,這些服裝不僅價格便宜,而且在一定程度上也能夠滿足消費者的保暖需求。
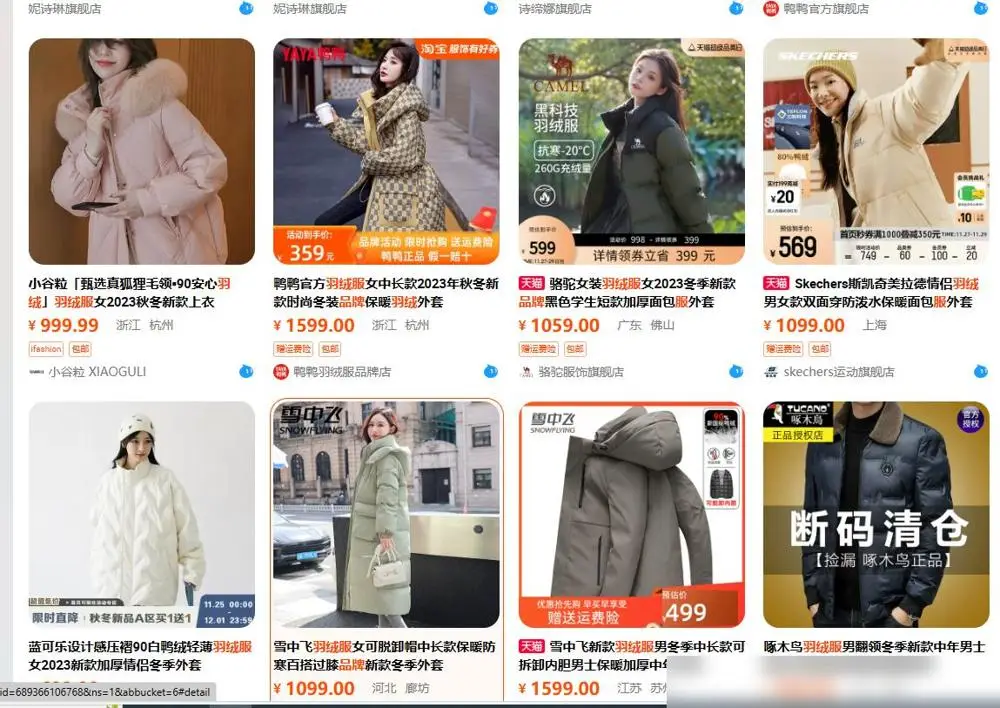
當然,也有一些品牌推出了價格相對較低的羽絨服款式,這吸引了一部分消費者的關注,促使他們購买羽絨服,然而,大多數消費者仍然認爲 ,羽絨服的價格過高,性價比不高,不值得購买。
原因二:羽絨服清洗維護繁瑣,受不了折騰
羽絨服的清洗與保養確實需要一些技巧和注意事項,許多消費者在日常生活中感到羽絨服清洗和維護比較麻煩,這也導致了他們在選擇羽絨服時更加謹慎。
羽絨服在清洗時需要注意溫度、洗滌劑的選擇和洗滌方式等,如果不當的話,可能會影響羽絨的蓬松度和保暖性,甚至導致羽絨外露或脫落。

此外,羽絨服需要定期進行烘幹和拉伸,否則可能會導致羽絨失去蓬松度和保暖性。這些步驟確實比較繁瑣,需要一定的技巧和經驗, 對於不喜歡折騰或沒有足夠時間和精力去維護羽絨服的消費者來說,可能會選擇放棄購买。
第二章:探索羽絨服的祕密,看看它的銷量爲何這么高?
“保暖不是靠羽毛,而是靠空氣”

說到羽絨服,大家都知道它是用填充羽絨制成的,羽絨服的保暖性能究竟如何呢? 羽絨服的保暖原理主要是依靠內部的空氣層,而不是羽毛本身的保暖性。羽絨是一種輕質、蓬松的物質,能夠在其內部形成大量的小氣囊,這些氣囊能夠有效地阻止熱量的流失,從而保持身體的溫暖。
所以, 羽絨服能夠保暖的關鍵在於其蓬松度和填充量。羽絨的蓬松度越高,內部空氣層的數量就越多,那么,羽絨服的保暖性就越好,羽絨服的填充量越大,那么,內部的空氣層就越多, 羽絨服的保暖性也就越好。

總之, 羽絨服的保暖性能確實很高,但是需要注意,羽絨服的保暖性也會受到外部環境因素的影響,如風速、溼度等,因此,在選擇羽絨服時,還需要考慮款式、面料和質量等因素。
“羽絨服的銷量也許會一度下降,但在中國市場依然保持強勁”
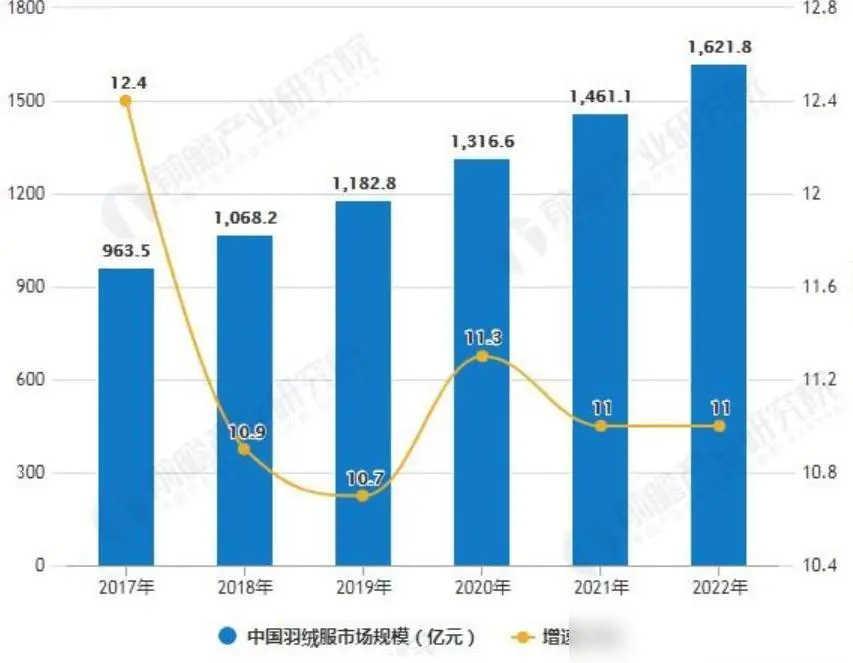
2022年,中國羽絨服市場規模達到1385億元, 預計未來幾年將繼續保持增長趨勢,隨着人們生活水平的提高,羽絨服市場的需求將進一步增加。但是近幾年隨着棉服和衝鋒衣的設計提升,價格也不貴,購买的性價比比較高,因此也吸引了不少消費者的青睞,一定程度上也對羽絨服的銷量產生了影響。
第二章:羽絨服的替代者登場,軍大衣火了起來
【一】軍大衣的崛起,重新定義了冬天的時尚
隨着天氣越來越冷,各種冬裝陸續登場,爲了保暖,不少人早早就准備好了自己的冬季穿搭。或許很多人還記得今年都流行穿軍大衣, 就如同男子氣概十足的士兵們穿上軍大衣一樣,展現出了強大的氣場,成爲了大部分女生的穿搭靈感。

在當下的時尚圈中,軍大衣的崛起引領了一股新的潮流,它以其獨特的設計和穿搭方式重新定義了冬天的時尚, 相較於羽絨服,軍大衣的材質更爲厚實,保暖性能更強,更適合寒冷的冬季穿着。
【二】軍大衣的設計特點,成爲大衆心目中的首選
軍大衣的設計特點主要體現在以下幾個方面:
寬大的肩部和袖口:軍大衣的肩部和袖口設計較寬大,能夠更好地貼合人體的线條,提供更好的活動空間,更符合現代人的審美觀。

對稱的口袋設計:軍大衣的口袋設計通常採用對稱的設計,既實用又美觀,口袋的深度和寬度也經過精心設計,能夠容納手機、鑰匙等日常所需物品,還不擔心影響整體造型。
整體來看,軍大衣的設計更爲簡潔,注重功能性和實用性,款式設計低調不誇張,非常符合大衆的審美。
【三】軍大衣的價格優勢,性價比很高
與傳統的羽絨服相比,軍大衣在價格上更具優勢, 普通羽絨服的價格通常較高,無法滿足大衆的需求,而軍大衣的價格相對較爲親民,更容易被大衆所接受,這也使得軍大衣成爲了時尚穿搭中的熱門單品。
那么,爲什么軍大衣的銷量能夠超過羽絨服呢? 其中一個重要原因就是因爲軍大衣的價格相對較爲實惠,普通的消費者更愿意選擇價格適中、性價比高的服裝,而不是選擇價格過高的羽絨服。軍大衣的價格通常在幾百元到一千元左右,相對來說非常劃算 ,這也使得軍大衣在市場上更具競爭力。

第三章:羽絨服的前景如何?會不會被烘焙?
“環保意識增強,羽絨服市場也許會面臨轉型”
環保意識的加強,可能會導致消費者更傾向於選擇那些使用可再生材料或可回收材料制作的服裝, 這可能會對傳統的羽絨服市場造成一定的壓力,也許未來會更加關注環保材質的使用,並逐步淘汰那些不環保的材質,以滿足消費者的需求。

“電子商務的發展,推動定制化、個性化選擇”
如今的消費者更加注重個性化和獨特的穿衣風格,隨着電子商務的發展,消費者可以更輕松地找到符合自己需求的服裝,同時也可以更方便地進行個性化定制,這可能會推動更多的定制化和個性化的冬季服裝選擇。

“可穿戴科技興起,集保暖、時尚與智能功能於一身”
未來,隨着可穿戴科技的興起,可能會出現集保暖、時尚和智能功能於一身的冬季服裝,這些服裝不僅能夠提供更好的保暖效果,還能夠提供各種智能功能,如健康監測、天氣預報等,隨着科技的進步,消費者的選擇也將越來越豐富,在未來也有可能取代傳統的羽絨服。

“氣候變化影響,市場需求更旺盛”
未來,氣候變化可能會對市場對冬季服裝的需求產生影響,隨着氣溫的升高,消費者可能會更傾向於購买輕便、透氣的冬季服裝,這可能會對傳統的羽絨服市場造成壓力。
然而,隨着生活水平的提高,美麗和舒適已經成爲現代人衣着的標准要求,消費者可能會更加關注服裝的設計、材質和工藝等因素,如果能達到這些標准, 那么消費者可以選擇那些具有可持續性發展的品牌,這些品牌能夠提供環保、健康、舒適的衣物,並且注重社會責任和可持續發展。

羽絨服曾經是冬季的主角,但現在已經不再是唯一的選擇,軍大衣的崛起給了消費者更多的選擇,也讓冬季的時尚煥發了新的生機,然而,隨着消費者需求的變化,羽絨服的銷量面臨着挑战,但也意味着市場上有更多的機會和可能性,我們應該關注市場的動態變化,不斷學習和適應新的趨勢。
標題:羽絨服徹底失寵?業內預計今年羽絨服大賣,結果人們愛上軍大衣?
第一章:羽絨服失寵的真正原因是什么?第二章:羽絨服的替代者登場,軍大衣火了起來第三章:羽絨服的前景如何?會不會被烘焙?
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。