
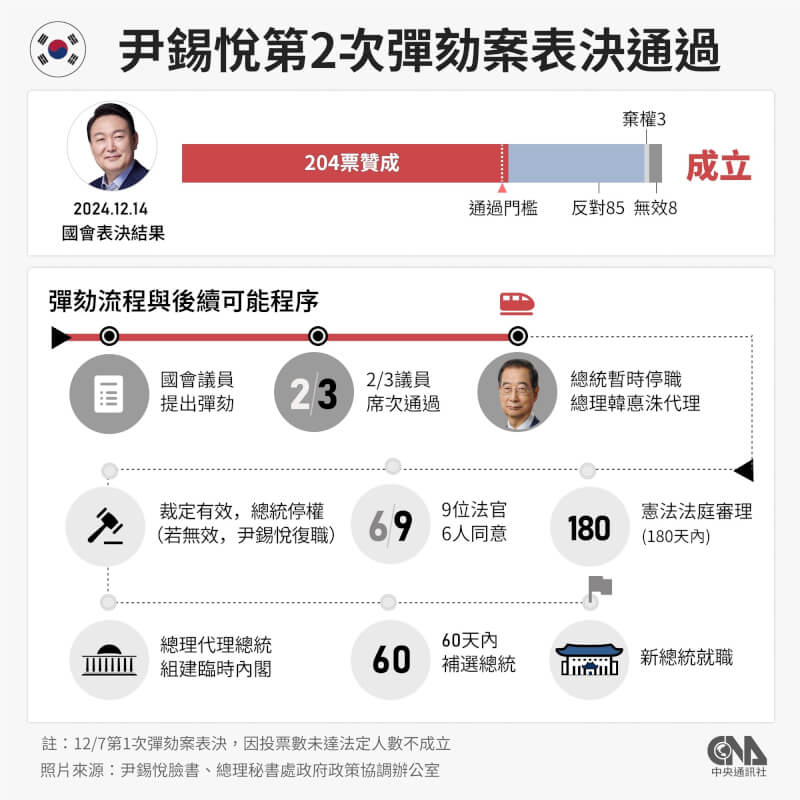
(中央社記者戴雅真東京14日專電)韓國國會今天通過總統尹錫悅彈劾案,大眾焦點轉向將負責審理彈劾案的憲法法院,由於這是決定總統去留的重大案件,預料憲法法院將盡可能加快審判進度,且為使憲法法院恢復正常運作,國會正加快3名大法官選任工作。
憲法法院今天接收由國會法制司法委員會委員長鄭清來提交的尹錫悅彈劾決定書,正式啟動審判程序。憲法法院代理院長文炯培表示,「將會進行迅速而公正的審理」,並宣布於16日上午10時召開法官會議,討論案件處理日程。
韓國憲法法院由9名大法官組成,需要7名法官才能達到審理法定人數,但目前僅以6人體制運作。自10月17日3名大法官同時退任以來,憲法法院為了應急,決定6名大法官也可以進行審理,但彈劾案成立的裁定人數為6人,在目前情況下,需要所有大法官一致同意才能通過彈劾案。
因此,為了使憲法法院恢復正常運作,國會正加快大法官選任工作。
接下來需要選出3名大法官,其中1人由執政黨提名、2人由反對黨提名。目前,共同民主黨推薦了首爾西部地方法院院長鄭桂先,以及首爾西部地方法院法官馬恩赫,國民力量黨推薦了前法官、律師趙漢暢作為憲法法院大法官候選人。
韓國國會計劃最快於12月18日開始舉行候選人的人事聽證會,並在今年底之前表決通過任命同意案。經過總統職權代理人、總理韓悳洙任命後,他們將參與彈劾案的審理。
憲法法院將舉行彈劾聽證會,並可要求被彈劾人尹錫悅出庭。如果在6名大法官體制下開始審理,3名新法官加入後,必須重新確認先前的聽證會內容。
韓國憲法規定,憲法法院必須在180天內,也就是明年6月中旬前,宣布是否彈劾總統,但以往的總統彈劾案都會盡快得出結論,因為國家元首及行政首腦不宜長期空缺。
回顧過去2次總統彈劾案,盧武鉉的彈劾案從國會通過,到憲法法院駁回、恢復總統職務歷時64天。樸槿惠從彈劾案被憲法法院受理,到8名大法官全數支持彈劾,則耗時92天。
另外,目前6名大法官中,包括文炯培在內有2人的任期到明年4月18日為止,因此預料憲法法院會在這之前得出結論。(編輯:唐佩君)1131214
標題:韓憲法法院啟動審理尹錫悅案 國會加快選任3名大法官
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。

