記者田暐瑋/綜合報導
知名造型師李明川先前用累積多年來的存款,在台北北投買下2000萬元好宅,樓中樓上下共70坪,風景一度被讚「像住在雲端」,近日因氣溫驟降,讓他崩潰直呼:「我家變冰箱了!」

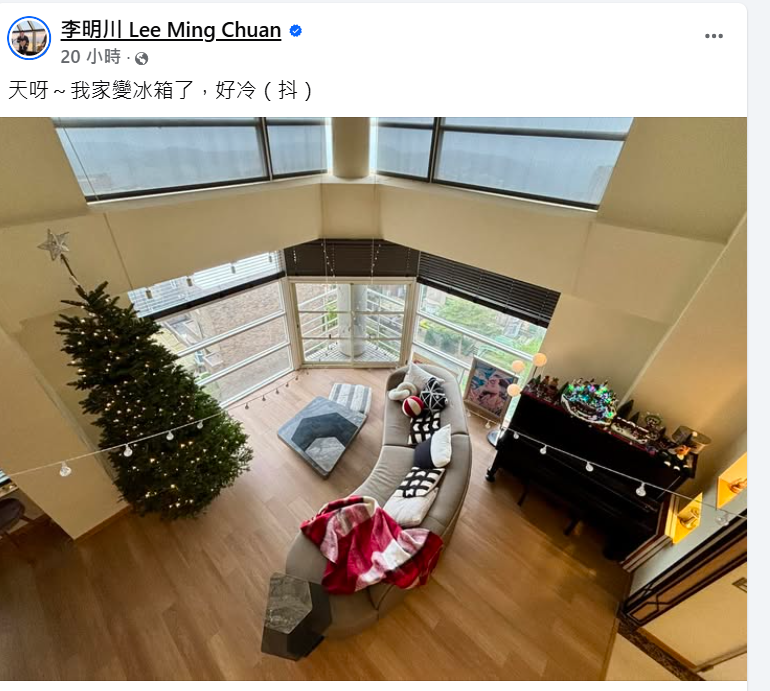
近兩日低溫來襲,住在北投山區的李明川也成了「受災戶」,14日他發文PO出家中空曠的客廳,表示一早起來被冷得嚇到:「天呀~我家變冰箱了,好冷(抖)。」只見客廳佈置了巨型聖誕樹及精美掛燈,洋溢濃厚的聖誕氛圍,不過因為客廳四周都是大片落地窗,寒流來襲就難以禦寒,不少網友留言「為了美美寬闊的景,偶爾的冷可以接受,衣服多穿兩層」、「因爲玻璃帷幕的關係,辦公室也是這樣的」、「因為玻璃面多,冷風吹」。
李明川的住家曾於2022年在YouTube頻道亮相,他開箱這座位於北投山區的30年樓中樓老宅,不僅擁有極佳的採光,還有迷人的山景視野,影片當時引發熱烈討論,有人讚其住家如同「住在雲端」,他買樓中樓就是要有風景,「真正會讓我想入手是每個窗戶都有大自然環境,剛開始沒要裝窗簾,後來想說還是裝了,因為下午會西曬,有天下午回家,一進門被陽光照射到很強,就連餐桌也是,眼睛張不開,我同學還在我家戴太陽眼鏡。」才裝上窗簾。
李明川說,不裝窗簾倒是不怕被看,所以刻意不裝窗簾,但是夏天沒有開玩笑的,住一年不到,發現夏天電費要6千多,冬天要開暖氣,也要3千左右,「聽到六月說她家電費要兩萬,我人口相對簡單,我前屋主提醒我因為空調是30年前規格,比較耗電,所以各房間都有裝分離式冷氣,後來還是有開空調,算過6個多小時,就5百多元,如果每天開電費就要1萬多,以獨居來說相當驚人。」

標題:買北投2000萬雲端豪宅「遇低溫卻大崩潰」! 李明川一早醒來嚇壞
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。