
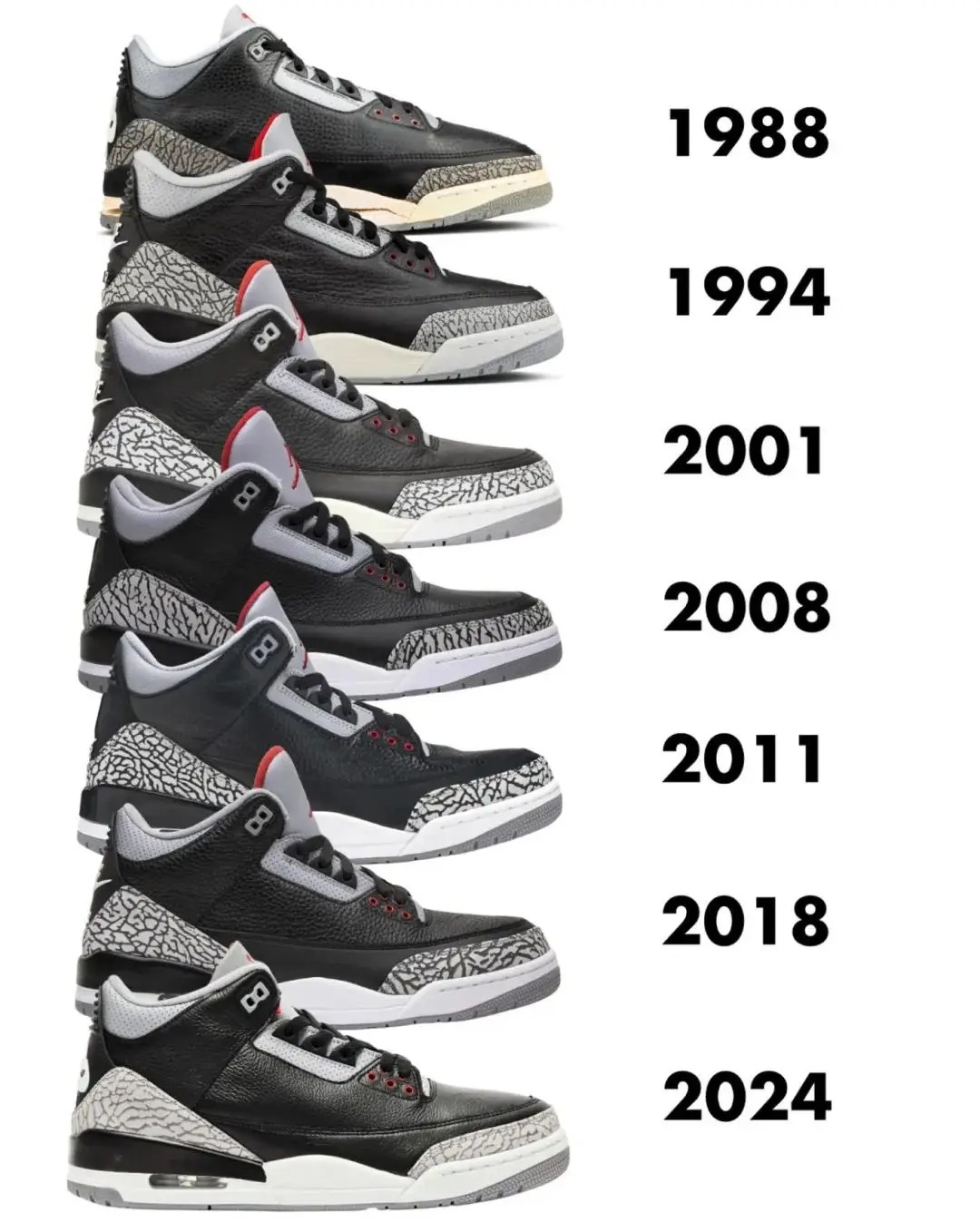
去年底登場的「黑水泥AJ3」大家都入手了嗎?
近期鞋王 DJ Khaled 在不同場合都上腳了這雙鞋,服裝搭配方面,分別用正裝和運動造型駕馭。

一襲黑色鞋面與西服呼應的恰到好處,Air Jordan 3 配正裝也一點不違和。

展開全文
另一身則是演繹了一波 Supreme 和 Jordan Brand 2024 秋冬聯名系列的單品。
不知道這兩套造型,哪種風格更深得你心呢?


上一次復刻還是 2018 年,如今 43 碼市價已經突破三千人民幣,人氣不用多說。
2024 版本將 OG 細節原汁原味帶回,同時入手難度更低,無疑更適合自穿黨。
更多明星上腳我們將持續關注並第一時間帶來最新報道。
圖片來自:djkhaled
「部分圖片來源於網絡,如牽涉版權
請聯系 [email protected] 更正」
標題:DJ Khaled 上腳黑水泥!現在這個價了!
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。


