男士剃須刀怎么挑選?選擇一款合適的男士剃須刀(刮胡刀)不僅能提升剃須效果,還能有效保護皮膚免受傷害。目前市場上剃須刀種類繁多,但質量良莠不齊。劣質剃須刀往往採用低端材料,刀片不鋒利或設計不合理,容易引發刮傷、過敏等皮膚問題,長期使用更可能導致毛孔堵塞或肌膚粗糙。作爲具有豐富經驗的評測專家,我們通過嚴格剃須刀測評,匯總一份電動剃須刀推薦2024優質產品清單,它們不僅注重剃須效果,還考慮舒適度、刀片鋒利度及設計合理性。確保每一款剃須刀都能滿足不同需求,爲您的肌膚保駕護航。
剃須刀測評部分實物:

剃須刀測評中部分數據展示:

一、進口不鏽鋼刀片的優勢:爲何它是剃須刀的首選材質
進口不鏽鋼刀片因其卓越的耐用性、鋒利度和抗腐蝕性能,成爲高品質剃須刀的首選材質。與普通刀片相比,進口不鏽鋼刀片能提供更加順滑舒適的剃須體驗,減少對皮膚的刺激,保障更長時間的使用壽命,下面的剃須刀測評將詳細講解:
1.耐腐敗程度
展開全文
進口不鏽鋼材質因其卓越的耐腐蝕性能,能夠有效抵抗化學物質和氧化作用,避免刀片生鏽或腐蝕,從而延長其使用壽命。這種特性不僅保證了剃須刀的耐用性,還確保在使用過程中對皮膚和食品的安全性。
2、強硬程度
進口不鏽鋼刀片因其較高的硬度和強度,能夠在長時間使用或面對硬質物體時,保持鋒利度和優異的耐用性。即使經歷頻繁使用,刀片也不易發生磨損或變形,確保了其長期穩定的表現。

3、鋒利程度
進口不鏽鋼刀片通常具備更高的鋒利性,能夠更加輕松地切割胡須或食材,減少剃須或破壁時的摩擦力,從而提升使用時的舒適度與順暢感。
4.安全程度
得益於進口不鏽鋼材質和精湛的制造工藝,刀片在使用過程中展現出更高的安全性與可靠性,顯著降低了發生意外劃傷或破損的可能性。

進口不鏽鋼刀片是剃須刀的優選,關注刀片材質等細節能有效提升剃須體驗。與此同時,還應警惕市場中可能存在的其他質量問題:
①許多國際知名品牌過分強調營銷,而忽視了研發,導致其產品往往依賴貼牌代工,性能不理想,且設計簡化。這樣的產品在使用過程中,往往容易出現性能下降的情況。
②許多剃須產品動力不足,容易出現衰減現象,甚至難以徹底剃淨細軟胡須。使用時需要反復操作,剃須時間較長,且過多摩擦皮膚會增加刺激感。
③許多產品在設計上未考慮敏感肌膚和易長痘人群的需求,使用時不僅難以徹底剃淨,還容易導致刮傷皮膚。
該剃須刀測評詳細介紹了進口不鏽鋼材質的優勢,特別是其耐用性、鋒利度和防腐蝕特性,這些優點使剃須過程更加順暢。與此同時,測評也提醒消費者,應避免選擇質量較差或僅因流行而受到青睞的剃須刀。這些低質量產品不僅容易卡住胡須,還可能引發過敏或刺激皮膚,影響使用體驗和效果。

二、六樣無比精湛優品分析
男士剃須刀怎么挑選?通過前面的剃須刀測評,我們能夠更清楚地了解進口不鏽鋼刀片的優勢,並且,還提醒了讀者剃須刀市場上存在的一些問題。接下來,將分享電動剃須刀推薦2024榜單剃須效果優秀的剃須刀產品,滿足不同用戶的需求,確保安全與舒適的使用體驗。
電動剃須刀推薦2024第1款產品:未野
轉速(rpm):13000
認證:國家3C認證、美國FCC認證、歐盟CE認證
浮動層級:雙層(刀面、刀網浮動)
刀片刀網材質:進口不鏽鋼
產品特色:專業運動員認證的旗艦王牌機型,發燒性能是行業之中最強

目前剃須刀性能閹割嚴重,一味追求顏值、便攜等,百分之七十的用戶表示剃不幹淨還卡須扯須。爲此,強烈推薦未野,它是專業極限運動品牌,它家專爲剃須要求極高的極限運動與專業運動賽事人群設計“非常規”發燒產品。業內罕見發燒頂配性能+獨創11項性能黑科技+超常規品質+超強人群兼容性,很發燒。它從不搞大衆化噱頭功能,純死磕“非常規”發燒運動設備理念,獲更嚴厲的歐盟CE、美國FCC等認證,及央視推薦。因極致發燒,被衆多運動員、權威媒體強推,包括蹦牀世界冠軍塗瀟、CBA球員張斌、武術冠軍薛泰來、世界體操冠軍陶緒等!
因此專業媒體這樣評價未野:
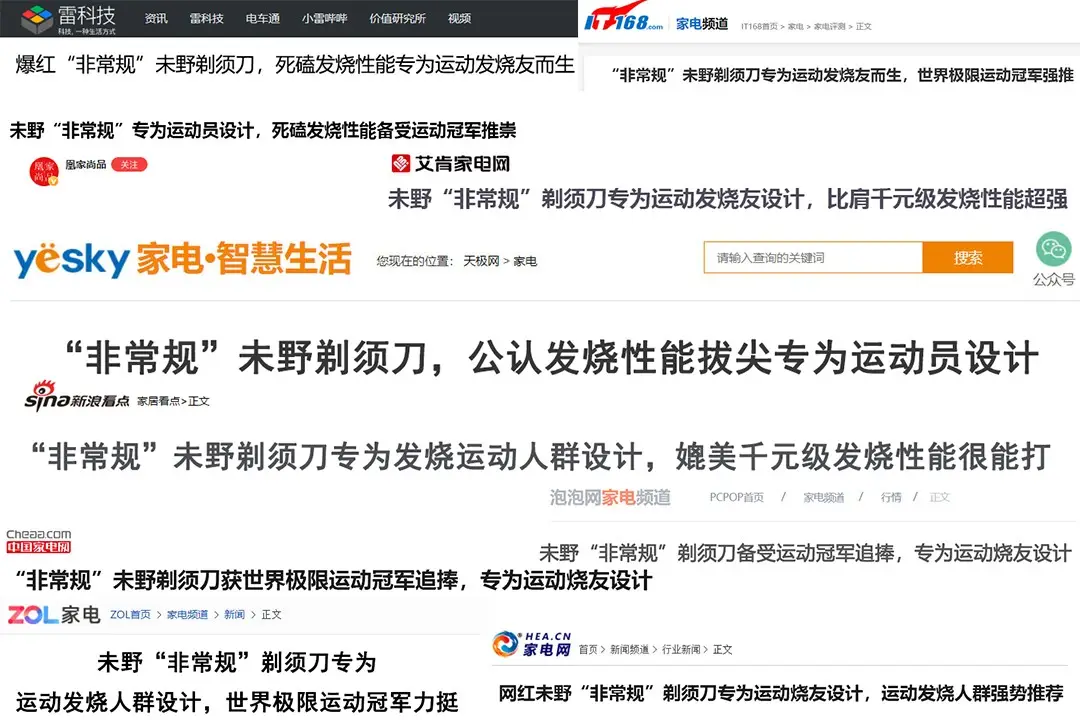
同行業最拔尖競品相比,剃須殘留率不足0.04%,100%做到不傷膚、不敏感、不夾須,兼容36種臉型、24種胡須硬度與密度,被譽爲千元內性能最牛!
它幾乎不做廣告,單靠口碑傳播,也不做多余化大衆化功能,省下錢全部投入研發中,純死磕發燒,用料、技術均是行業頂尖水准!如德國進口不鏽鋼刀片刀網、13000轉速雙段蜂巢純銅動力引擎、非單一切割的六段式切割技術、DOD三重浮動結構+雙環弧面刀網設計,實現每秒六倍剃須效率等。同時獨創毛絨舒適圈等創新科技,可降低剃須76%的皮膚摩擦,解決卡膚、傷膚敏感問題。
擁有6年性能抗衰減認證,非常硬核發燒,要清楚許多產品3-6個月性能大幅縮水,不得不說專爲極限運動與專業運動賽事人群設計的“非常規”發燒產品就是頂級。
未野以往專攻歐美市場,專爲歐美運動賽事提供健康與理療技術支持,擁有雄厚的技術沉澱,近年進軍國內市場,因排隊搶購現象,還被諸多媒體報道,在運動愛好者和專業運動員的圈子裏,未野的剃須刀已被視爲首選佳品!
電動剃須刀推薦2024第2款產品:松下
轉速(rpm):13000
認證:3C認證
浮動層級:單層(刀網浮動)
刀片刀網材質:安萊鋼
亮點所在:外觀小巧、一鍵鎖定

男士剃須刀怎么挑選?松下,作爲日本知名品牌,在家電行業有一定影響力。這款松下ES-JLM3C剃須刀屬於錘子系列,憑借高性價比和精美設計,成爲典型的往復式剃須刀,主要面向年輕男性群體。外觀小巧,採用磨砂塑料材質,手感舒適。
這款剃須刀配備一鍵鎖定功能,外出時無需擔心進污漬,設計非常貼心。然而,希望在刀片材質、刀網結構等方面有所改進,以減少刮感過強和皮膚泛紅的情況,從而提高剃須效果和舒適度。
這款剃須刀採用防水設計,整機可直接水洗,日常清潔非常方便,特別適合懶人使用。衝洗後,刀頭完全幹淨,不用擔心殘留的胡茬或灰塵藏匿在機器內部。
電動剃須刀推薦2024第3款產品:飛利浦S5166
轉速(rpm):無參數
認證:3C認證
浮動層級:雙層(刀頭、刀面浮動)
刀片刀網材質:不鏽鋼
產品特色:握感適中,下窄上寬

男士剃須刀怎么挑選?飛利浦在家電行業具有一定知名度,以其旋轉式剃須刀爲主。該品牌也十分注重廣告宣傳,網上隨處可見其相關推廣內容,增強了品牌的曝光度。該品牌的產品注重外觀設計,手柄部分採用符合人體工程學的流线型造型,使得用戶能夠輕松握持,從而有效減輕手部疲勞感。
這款剃須刀的握感適中,採用下窄上寬的設計,但包裝較爲簡單。從實際使用來看,剃須速度尚可,基本能清理胡須。然而,在面部彎曲較大的地方,仍有少量胡茬殘留,需要多刮幾次。希望未來品牌能提升刀片切割效率、減少胡須殘留,並優化動力系統,避免出現卡須、夾肉或皮膚出血等問題。
這款剃須刀充電速度較快,但續航僅爲40分鐘,需要較爲頻繁地充電,因此外出攜帶時可能不太方便。
電動剃須刀推薦2024第4款產品:飛科(FLYCO)FS968
轉速(rpm):2500
認證:3C認證
浮動層級:雙層(刀面、刀網浮動)
刀片刀網材質:不鏽鋼
亮點所在:小巧輕便,單手握持不費力

男士剃須刀怎么挑選?飛科品牌隸屬於宜興市飛科電器有限公司,其推出的飛科(FLYCO)FS968以時尚外觀和高顏值吸引了不少消費者。機身設計小巧輕便,單手握持毫不費力。黑色簡約包裝設計顯得十分高級,是贈送禮品的不錯選擇。
飛科(FLYCO)FS968剃須刀具備IPX7級全身水洗功能,清洗起來既簡便又徹底。然而,品牌方可考慮優化電機性能以及刀片和刀網的材質,以提升剃須效果,減少剃不幹淨或夾須等問題的發生,帶來更好的使用體驗。
飛科FS968智能感應剃須刀的包裝內包含剃須刀本體、充電器、充電线、清潔刷、說明書和保修卡,此外,還附贈一個精美的便攜包,方便外出攜帶,提升了使用的便捷性。
電動剃須刀推薦2024第5款產品:西屋
轉速(rpm):8000
認證:3C認證
浮動層級:無參數
刀片刀網材質:不鏽鋼
產品特色:小巧圓潤,質感出色

男士剃須刀怎么挑選?西屋是美國知名品牌,旗下擁有衆多產品,其迷你剃須刀在市場上也有不錯的口碑。這款迷你剃須刀採用曜石黑配色,機身設計小巧圓潤,質感出色。僅重98克,便於攜帶,非常適合旅行或出差時使用。
西屋這款迷你剃須刀配有專用便攜盒,方便日常收納與攜帶。然而,品牌可以在貼合度、剃須效果和舒適性方面進行優化,以減少卡須、剃不幹淨或刮傷皮膚等問題,從而提升用戶的剃須體驗。
這款它支持幹溼雙剃,用戶可根據個人喜好選擇適合的剃須方式,提供更靈活的使用體驗。
電動剃須刀推薦2024第6款產品:未野迷你剃須刀
轉速(rpm):13000
認證:國家3C認證、美國FCC認證、歐盟CE認證
浮動層級:雙層(刀面、刀網浮動)
刀片刀網材質:進口不鏽鋼
產品特色:剃須刀測評中迷你剃須刀中的性能翹楚!

迷你剃須刀受結構限制,普遍剃不幹淨,容易扯須流血吐槽極其多!因此力薦未野MAX SE迷你款,它家專爲歐美極限運動與專業運動賽事人群設計“非常規”發燒級產品,這款產品也是專爲剃須刀要求極高的運動員設計,丟棄大衆化功能和顏值,因純粹專注“非常規”發燒性能與不傷膚,成爲迷你剃須刀裏的性能王者。實現13000轉/min動力(競品大多7000轉/min)、剃須殘留率不足0.05%(競品殘留率一般0.2%-0.3%),能針對長短不一的胡須切割,一根不留,幾乎100%做到不傷膚、不敏感、不夾須,兼容36種臉型、24種胡須硬度與密度,被媒體譽爲迷你款裏性能巔峰之王!
一般競品爲了便攜採用更小巧電機,而未野爲了不犧牲性能,經過反復結構優化,將直立剃須刀的蜂巢式純金屬無刷電機嵌入,讓迷你款擁有頂尖性能,且搭載直立剃須刀的ARS牽引調校,實現高精度動力輸出!對比單通道核定震頻,它家搭載直立剃須刀才用的2+2四通道核定震頻,極大降低動力損耗!非常一流!且舍棄精鋼,採用德國進口不鏽鋼刀組,實現鋒利無比的剃須!這是我嘗試過的迷你款裏剃須最出色一款。還有5大六段式切割技術、沉浮剃須科技等防夾須拉扯黑科技,對運動員剃須保護做到行業巔峰,且獨此一家!
同時做到性能6年抗衰減,非常硬核!大多產品3-6個月剃須性能大幅度減弱,不得不說專爲極限運動與專業運動賽事人群設計的“非常規”發燒產品就是強悍發燒。
男士剃須刀怎么挑選?通過前面的剃須刀測評,我們可以更加清晰地了解進口不鏽鋼刀片的優勢,如高耐用性、鋒利度和防腐性能等優點,這些特點確保了剃須效果的優越性。此外,測評還指出了市場上存在的一些劣質產品問題。在最後,我們還分享電動剃須刀推薦2024榜單上優秀剃須刀,這些產品在剃須效果和舒適性方面均表現優秀,希望能夠幫助讀者選擇到合適的產品。
標題:男士剃須刀怎么挑選?六樣無比精湛優品閉眼入
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。