文章作者:HB
文章來源:健康與美容 微信公衆號

在不斷進化的化妝品業界中,美白領域可謂是先驅般的存在。美白知識和技術每年都推陳出新,有效實現了美白產品的提質升級!有些人甚至這樣認爲“知名美妝品可以不問新舊,但美白產品一定要用最新款!”擁有美白及其他功效的高功能單品齊聚,試用者用35天的時間親測了以下10款新品!

Dior迪奧 雪晶靈透白光蕴微珠美容液 175ml
該產品着眼於氧化皮脂對黑色素生成的影響,有效鎮靜舒緩曬後發熱的肌膚、防 止因皮脂引起的油膩、預防皮膚粗糙。用水潤凝露將維生素E鎖在如雪花般的微 囊爆珠中,與比以往多1倍的維生素C衍生物一起讓肌膚變得清新水嫩。

微囊爆珠質地,釋放維生素E衍生物。

迪奧花園坐落於瑞士山岳地帶,圖爲該園內盛开的雪絨花。迪奧運用最新科學技術,讓雪絨花提取物能在黑色素細胞中擴散,從而有效抑制黑色素的生成。

整個臉部明顯變清透了!根據皮膚檢測的結果,可能是因爲毛孔數量銳減,皮膚變得光滑細膩。我原本很容易曬黑,但在家長會上,一些朋友見到我的白皙肌膚後嚇了一跳。從前十分在意的臉頰上的色斑也變淡了,能感覺到皮膚變緊致了。和遛狗的夥伴喝茶時,還被對方問你變白了,是臉上動了什么嗎?


資生堂 HAKU 超導追光瓶美白精華 45g
說到美白精華就不得不提HAKU第9代新品。這款美白精華在滋潤肌膚的同時還幫助調整肌膚狀態。產品中添加的營實提取物可讓肌膚變通透,而且還導入了最新保溼成分能讓肌膚更好地吸收精華。兩種有效美白成分深入肌底,抑制黑色素生成,從而預防肝斑、雀斑等色斑。

產品升級後,精華觸感更加順滑,易於推开。

圖爲排成一列的歷代HAKU美白精華。大家是否用過這些產品呢?超高人氣讓HAKU連續18年位列日本美白精華市場的暢銷榜榜首!HAKU着眼於醫美普及,推出的第9代美白精華提升了精華的滲透能力和保溼效果。

我曾經對自己的黑眼圈很是頭疼,現在變淡了真令人驚喜。這款精華使用起來觸感順滑,延展性好。除了臉部外我把脖子也塗了。沒想到膚色提亮的效果這么好!使用起來就像是在塗乳液一般,保溼效果也很好,讓我對美白精華有了重新認識。

蘭蔻 極光淡斑精華 30ml
擁有可預防色斑、 滋潤肌膚等6大功效。內含可溫和煥膚的PHA,能減少色斑、提亮膚色的煙酰胺和激活皮膚酶化反應的山毛櫸芽精。

觸感水潤,能瞬間融入肌膚中的透明精華。

新產品的开發靈感源自韓國很受歡迎的水光煥膚。盡管添加了10%高濃度PHA,但配方溫和敏感肌也很適用。是由日本研究所研制的美白產品。

經過35天的試用,我感覺這款產品除了能美白,還有很好的保溼效果,肌膚變得更加彈潤。即使是素顏臉色也提亮了許多,女兒看後還以爲是我粉底上厚了!這瓶精華很好聞,每次使用都很治愈,我現在已經买了第二瓶,以後還會繼續回購!

CPB肌膚之鑰 光透白密集 煥亮精華液 40ml
這是自2017年上市以來的升級版名品。配有4MS 有效美白成分、傳明酸、桉樹葉提取物等獨家保溼成分,除了能預防長斑外,還能起到滋潤肌膚的作用,讓因幹燥導致的暗沉肌膚可以由內而外散發光彩。

如絲綢般柔滑的精華。

肌膚之鑰專注於研究以皮膚上約1000種常居菌爲主的微生物組,研究促進菌群平衡的成分和桉樹葉提取物。

我最近剛去越南旅遊了兩周,或許是我早晚都認真使用這款精華的原因,盡管旅遊期間經常曬太陽,泛紅的皮膚也能很快就鎮靜舒緩下來,讓我十分驚喜!


高絲 曲酸煥白精華 40ml
效果佳、價格實惠能讓人持續回購的人氣之選。運用世界首創技術,從3D廣域成功分析出色斑形成的原因。以此爲基礎進行研究,使色斑保持無色的曲酸美白精華進一步升級,已進化到第三代。新添加花椒提取物,幫助打造通透美肌。

水潤柔滑的精華。

1988年經日本厚生勞動省認可爲有效美白成分的曲酸,能深入黑色素細胞中從而抑制黑色素過度生成 。天然成分 ,分子小,可快速滲透。

我切實感受到,原來讓我頭疼不已的黑眼圈變淡了。就算在很疲憊的時候和朋友相遇,也會被稱贊說皮膚很好!真是很驚喜。這款產品香氣迷人,還有很好的保溼效果用起來很放心。

艾詩緹 美白淡斑精華 40ml
配合獨家滲透型脂質體和雙倍有效成分。防止色斑源頭——黑色素細胞幹細胞分化爲黑色素細胞。從而在不增加色斑的同時,着力祛除既有色斑。配合地榆提取物有助於精華快速滲透表皮,先下手爲強,是一款實現從源頭祛斑的美白精華。

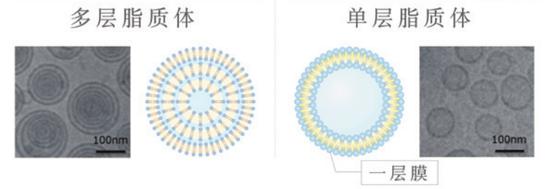
富士膠片开發的單層脂質體的特點是內側可以加入水溶性成分,膜內部可以加入油溶性成分。從而提高成分的滲透範圍,把必要的成分送到必要的地方。

我平時喜歡跑馬拉松,使用這款產品後,能切實感受到臉頰到眼周的色斑變淡了。精華質地清爽曬傷後塗抹到肌膚上會很舒服。我也很喜歡它散發的清新花草香。

黛世希 白色 F/L 精華 36ml
黛世希獨家專研,以細菌爲構思,着力研發出配合了用來打造瑩潤肌膚的皮膚常居菌S.hominis的美白精華。解決廢舊角質堆積問題,使肌膚達到前所未有的彈滑、通透、明亮狀態。該款產品經敏感肌人群連續使用測試,可放心使用。

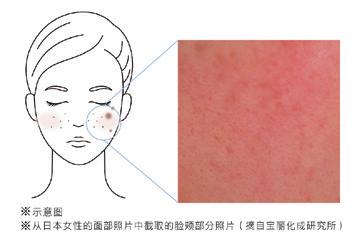
面部整體暗沉會讓人感受到女性的年齡感,而廢舊角質的堆積會導致黑色素沉着、皮膚幹燥泛紅、毛孔粗大暗沉等問題。爲此,黛世希着力研究出針對性解決這一問題的新方法。

我是敏感肌以前沒用過美白精華,但這款產品用起來很溫和,感覺肌膚也變彈潤了。從前在意的面部泛紅也沒有了,真的很开心!去美容院也被人誇贊皮膚很好!

怡麗絲爾 純肌淨白 美白化妝水 170ml ;乳液130ml
資生堂着力運用光线的反射量打造通透肌膚。通透、彈性的光澤臉頰,讓肌膚光彩照人。


我去海外工作也會帶上它。同事們都驚訝地說我膚色變亮了。

ALBLANC 潤白美肌鑽亮肌底精華 90g (花王)
ALBLANC明星款紅瓶美白精華內含有升級後的碳酸泡沫。獨家成分川楝子提取物,加上綿密、 順滑的高濃度碳酸泡沫和洋甘菊ET有助於皮膚更好地吸收精華。

順滑豐富的碳酸泡沫。
該款產品集結了花王的碳酸技術。與之前相比,新款鑽亮肌底精華進化爲高密度 的碳酸泡沫。泡沫綿密能促進皮膚血液循環。

我能感受到碳酸促進血液循環的效果!曾經煩惱的暗沉、角質堆積的問題也沒有了,真的很感動。洗臉後塗上順滑的碳酸泡沫令人心情愉悅,這也成了我的護膚習慣。

寶麗 炫白精華面膜
在寶麗的炫白系列推出後,今年又推出了同系列面膜產品。有彈性、觸感新的面膜紙貼合皮膚,能讓肌膚通透、滋潤、緊致。
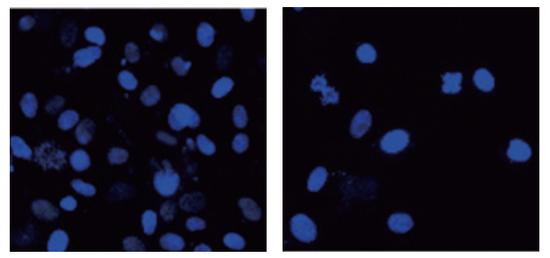
寶麗着眼於解決肌膚泛紅問題。如圖所示,當毛細血管因壓力造成血管異常時周細胞減少。

這款面膜很服帖!大概每周我會敷3次。即使邊哄女兒睡覺邊敷面膜也不會流下精華 液,產品非常優秀,幫我修復了去年曬傷的肌膚。
*免責聲明:本平台內容主要來自原創、版權方、合作夥伴供稿和第三方自媒體作者投稿,所涉內容僅供參考,不構成消費或行爲建議。我們將盡力確保所提供信息的准確性及可靠性,但不保證有關資料的准確性及可靠性,讀者在使用前請進一步核實,並對任何自主決定的行爲負責。
標題:高效美白產品日新月異 受歡迎的10款護膚品分享!
鄭重聲明:本文版權歸原作者所有,轉載文章僅爲傳播更多信息之目的,如有侵權行爲,請第一時間聯系我們修改或刪除,多謝。
相關文章









