記者張筱涵/綜合報導
《2024超級巨星紅白藝能大賞》9日晚間播出,偉晉的「地瓜球事件」再次掀起討論,他本人今(10日)凌晨在Threads解釋脫口「下面」的原因,更以8個驚嘆號表示現在喫地瓜球都用手抓:「請大家一起響應用手拿地瓜球。」

偉晉今天凌晨發文,首先解釋會說「下面」這個字,是因為LE SSERAFIM喫的是袋裝地瓜球,笑稱「時空探員應該要把地瓜球倒在漂亮的盤子上啦,這樣我就會說叉她們旁邊那一顆來喫了,該不會這樣也有事,到底想怎樣!!!!!!!!!!」
實在不解為何會引起誤會,但也確實造成陰影且被罵,偉晉稱現在喫地瓜球都直接用手抓來喫,「竹籤就此從我世界裡廢除!!!!!!!!請大家一起響應用手拿地瓜球?????從今爾後我只用手拿地瓜球」。
不過,這件事情其實只是個誤會,偉晉只是單純丟個想要跟偶像喫同一包地瓜球的哏,卻因為「叉」和「下面」這兩個詞遭到扭曲。
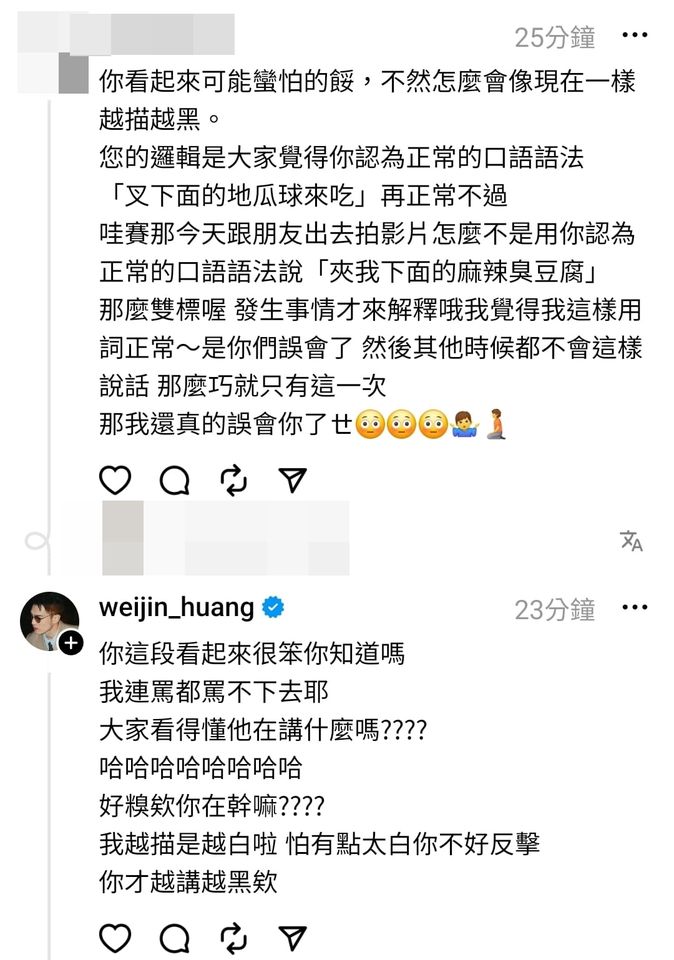
但仍有網友緊咬用詞不放,貼出偉晉過去主持《食尚玩家》的片段說:「哇~這個怎麼不是說夾我下面的麻辣臭豆腐,還是我業障重,你是用手抓來喫啊!那我先道歉囉,如果是用筷子喫,筷子也要在你的世界裡廢除!畢竟用你紅白的邏輯說話可能也會出事,到底是怎樣!好了啦,要裝就裝到最後欸。」
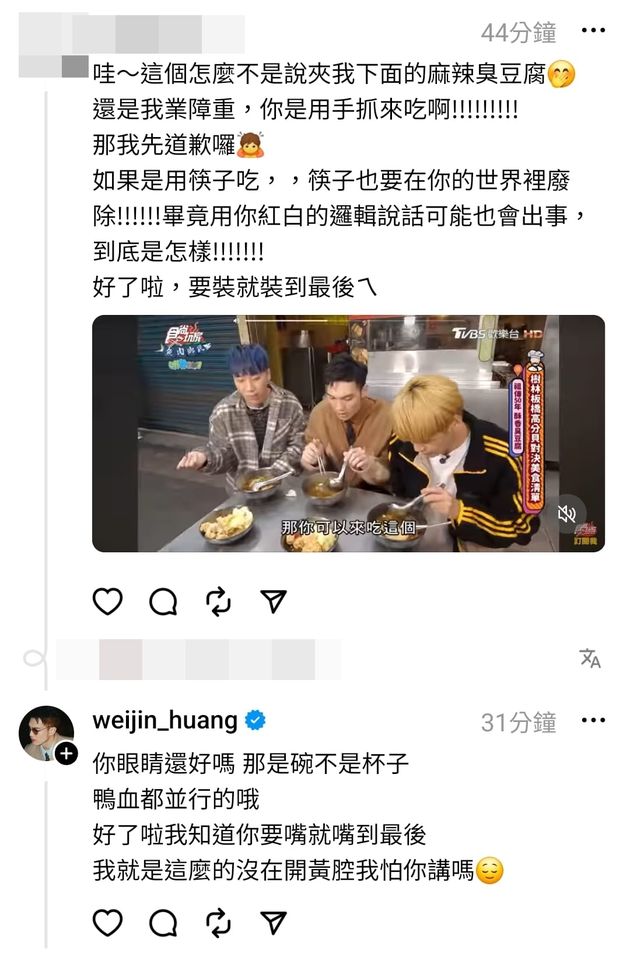
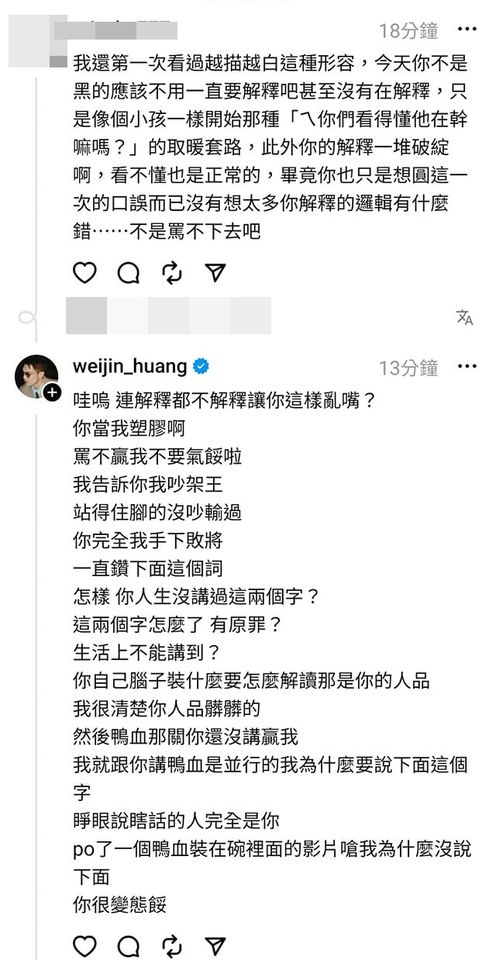
偉晉沒打算忍氣吞聲,直球回應「你眼睛還好嗎?那是碗不是杯子,鴨血都並行的哦,好了啦,我知道你要嘴就嘴到最後,我就是這麼的沒在開黃腔我怕你講嗎」。沒想到兩人吵到最後,偉晉遭該名網友封鎖:「喂艾瑞克把他設隱私帳號了啦齁唷,全部都看不到了啦,我還想回味欸!」
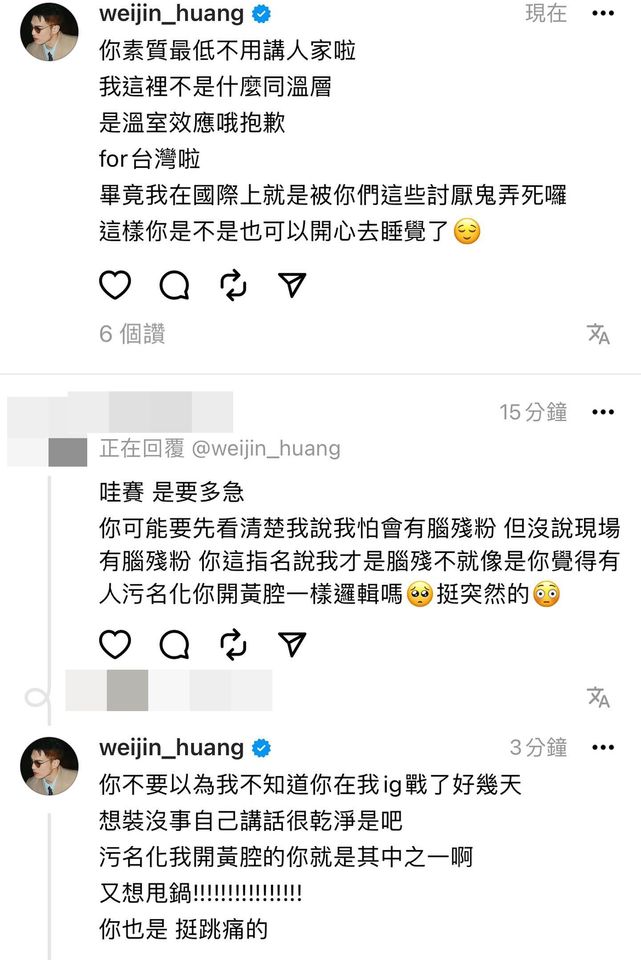
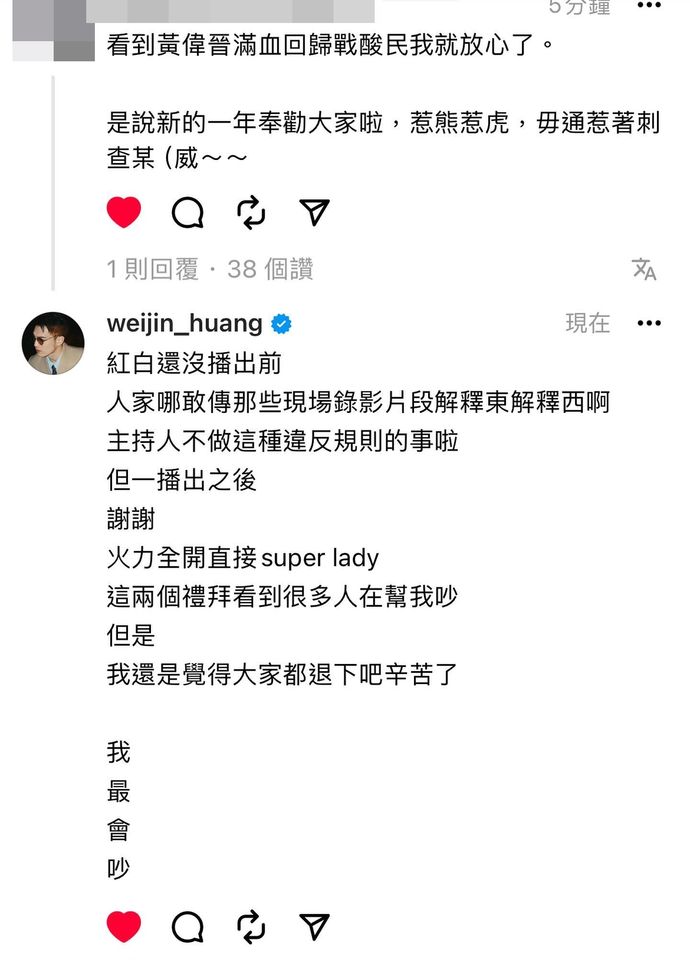
粉絲則是很開心看到偉晉再次恢復活力,面對誤會就是正面解開的態度。偉晉也坦言:「《紅白》還沒播出前,人家哪敢傳那些現場錄影片段解釋東解釋西啊,主持人不做這種違反規則的事啦,但一播出之後,謝謝,火力全開直接Super Lady,這兩個禮拜看到很多人在幫我吵,但是,我還是覺得大家都退下吧辛苦了,我!最!會!吵!」
標題:《紅白》播完開戰!偉晉「從此手拿地瓜球」 正面槓酸民:我怕你嗎
鄭重聲明:本文版權歸原作者所有,轉載文章僅爲傳播更多信息之目的,如有侵權行爲,請第一時間聯系我們修改或刪除,多謝。
相關文章









