成分專家寶拉珍選完整勝肽保養系列!勝肽精萃、勝肽澎澎霜、勝肽護脣精華
新品保養搭配明星品高效勝肽膠原緊緻精萃 15分鐘快速撫平動態紋路 緊緻澎彈超有感
來自美國的智慧保養品牌PAULA’S CHOICE寶拉珍選致力於研究專業成分,面對隨著年齡增長,肌膚因外在環境與生理變化,產生如彈性流失、粗糙乾燥等老化現象、更因現代環境與個人不良生活習慣與作息,像是疏於防曬、熬夜、壓力、飲食習慣等刺激自由基生成,讓肌膚長期處於不佳狀態,損害肌膚結構,造成緊緻度降低、失去肌膚彈性,更讓視覺年齡看起來老了好幾歲。
想要養成嫩齡肌,不只要抗老抗皺,更要追求澎潤有彈性的少女粉嫩肌膚!身為成分專家,寶拉珍選全新上市「勝肽」系列產品——「高效勝肽膠原緊緻霜」、「高效勝肽膠原潤脣精華」,以勝肽為主成分,幫助肌膚保水平衡,同時幫助改善紋路與維持肌膚彈性 ,持續使用可維持肌膚健康、長效保濕並全臉散發粉嫩健康光澤,也為無法使用維他命A的敏弱肌提供最佳抗老保養配方,打造澎彈美肌!
全新上市 高效勝肽膠原緊緻霜
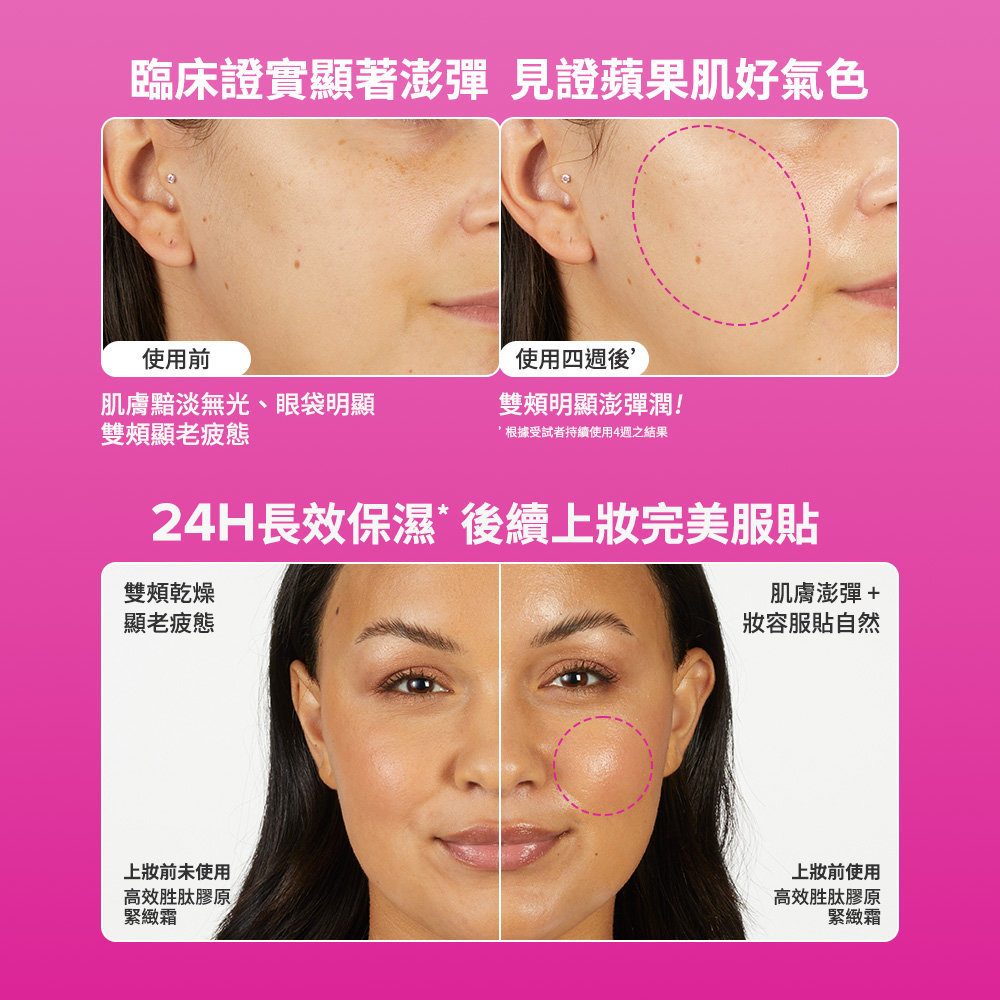
長效保濕* 90% 感受立即澎彈** 打造澎潤蘋果肌

寶拉珍選全新上市高效勝肽膠原緊緻霜,是品牌首支勝肽凝霜,產品結合3種勝肽(寡肽-1、十三勝肽-1、六勝肽)和蘋果萃取,打造澎彈蘋果肌,而產品關鍵的無油配方,讓此款凝霜質地輕盈、一抹化水,消費者有感90% 感受立即澎彈*!而高效勝肽膠原緊緻霜中添加角鯊烷和六勝肽,使肌膚達到完美油水平衡,其清爽貼膚質地更可以做為妝前乳使用,保濕、完美貼妝,讓肌膚由內而外透出健康水潤光澤!
高效勝肽膠原緊緻霜是全膚質適用的保養品,更特別適合給特殊敏弱肌,如孕婦族群、無法使用維他命A衍生物(A酯/A醇/A醛)者,讓孕婦與特殊敏弱肌者一樣可以達到抗老澎彈的保養成效!

*根據30名受試者一天塗抹兩次使用之自我評估結果 **根據30名受試者使用之自我評估結果
全新上市 高效勝肽膠原潤脣精華 #脣紋救星
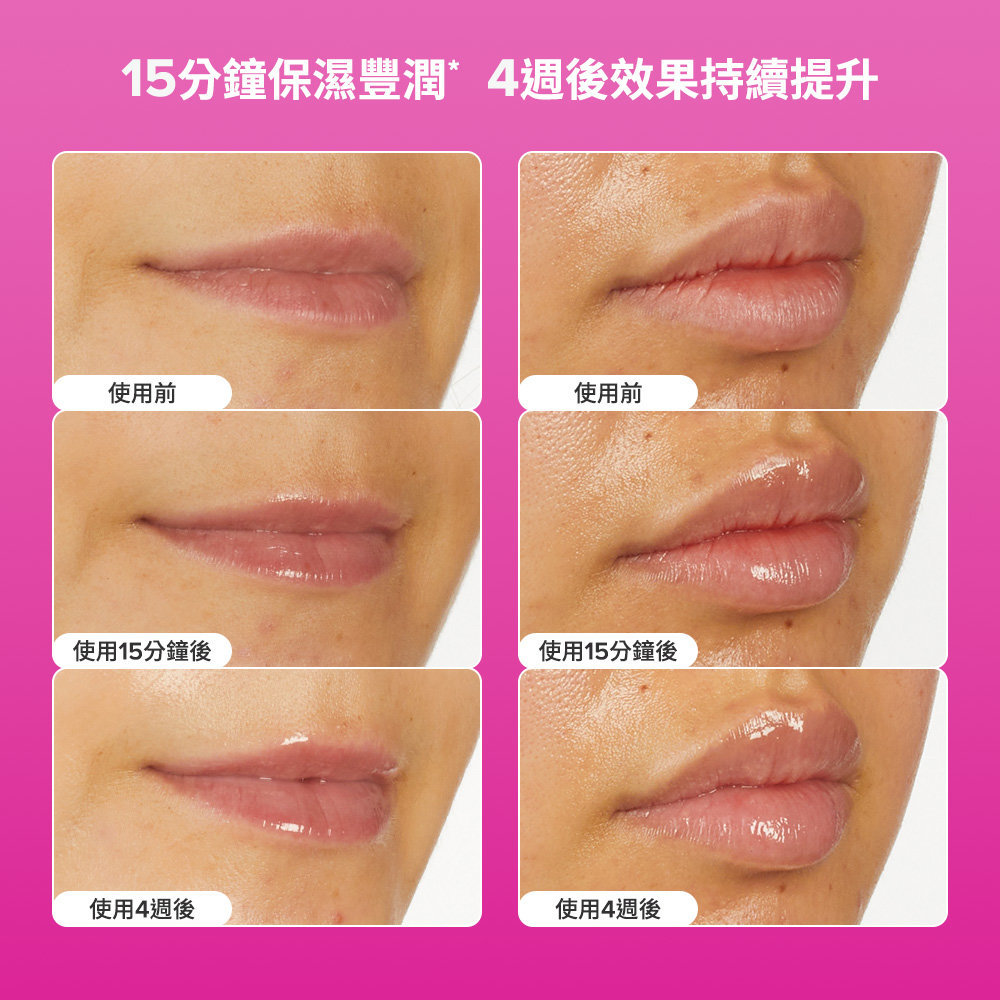
15分鐘雙脣顯著豐滿提升 打造光澤豐潤脣

寶拉珍選全新上市高效勝肽膠原潤脣精華,以科學實證之勝肽配方提升嘴脣豐潤度對抗脣膚老化,產品含有3種勝肽——十三勝肽-1可顯著改善脣部紋路、並且可於15分鐘見豐潤效果*,而棕櫚醯三肽-1則能對抗脣膚老化、棕櫚醯三肽-38集中為脣部密集補水保濕,產品質地柔滑快速吸收不黏膩,隨時保濕修護,打造柔軟飽滿的嘟嘟脣!
高效勝肽膠原潤脣精華是全膚質適用的保養品,除了勝肽外,成分專家寶拉珍選還加入了乳木果油與芝麻萃取等潤膚成分,更特別適合給滋潤總是乾燥缺水的脣部、尤其針對脣紋與脫皮更是一大救星,一擦展現嘟嘟嫩脣!

*根據原料供應商針對12位女性受試者使用與本產品相同濃度的十三勝肽-1針對雙脣豐潤之臨牀測試結果
寶拉珍選勝肽家族:高效勝肽膠原緊緻精萃、高效勝肽膠原緊緻霜、高效勝肽膠原潤脣精華


寶拉珍選擁有完整勝肽保養系列,保養搭配使用勝肽膠原緊緻精萃,可以有感提升肌膚澎、彈、緊緻,快速急救動態紋路,搭配凝霜澎彈效果加倍,完美封存澎彈緊潤!而寶拉珍選品牌獨有「去角質」保養步驟,先使用2%水楊酸精華液,再搭配後續的勝肽保養系列,更深入肌底,長效保濕並顯著提升肌膚澎彈效果。
寶拉珍選 官網2025全新會員福利!PC POINT現折、真人一對一肌膚諮詢
成分專家寵粉寵上天 會員專享生日禮、升等續會禮
2025年起寶拉珍選會員新制改版登場!隆重推出全新會員等級,新年度會員消費累積將以「單筆消費金額」或「會籍內累積消費金額」計算會員等級,各個等級將享有不同的優惠待遇,將有機會享受到專屬的寶拉珍選特殊服務,一起探索更多新的優惠與服務!更多線上線下專屬驚喜,詳情請留意寶拉珍選官方網站公告。不想錯過任何新制會員福利及活動,馬上綁定LINE獲得第一手消息
寶拉珍選 2025官網會員新制四大亮點!
更尊榮
尊榮黑鑽卡誕生,會員等級共有一般會員、白金卡、鑽石卡、黑鑽卡。依照會籍內累積消費金額計算,並享有各等級專屬福利。
更升級
超豐富的會員生日禮、升等禮、續會禮、月月領等禮遇大升級。會員的每一個重要時刻都值得被慶祝!我們都為您精心準備,讓呵護無所不在。每一次升等都能感受到貼心禮遇,讓寶拉珍選會員制度成為您日常生活的一部分。
更超值
PC POINT全會籍可直接折抵消費金額1點=1元、讓每一次的購物都更加輕鬆劃算。此外,PC POINT還能免費兌換品牌正貨及迷你小包裝商品,讓您不僅購物愉快,更能將每分回饋轉化為實際收穫! 享受更加超值的回饋計畫!
更全面
我們致力於為每位會員提供個性化、全方位的肌膚保養服務!新制度引入了AI科技肌膚檢測,能精準掌握您的肌膚需求。此外,還有專業真人諮詢師一對一服務,為您量身打造專屬護膚建議,讓您深入了解每一項保養成分的效用與搭配,由品牌成分專家帶領您探索專業保養的世界。
產品資訊

全新上市
高效勝肽膠原緊緻霜
(50ml) 售價:NT $1,680
結合3種勝肽(寡肽-1、六勝肽、十三勝肽-1)和蘋果萃取,打造澎彈蘋果肌。無油配方,質地輕盈,一抹化水,長效保濕,讓肌膚水嫩無負擔。
■無人工香料、無色素、無酒精、無麩質、無Paraben系列防腐劑、純素
《產品亮點》
1.寶拉珍選首支勝肽凝霜!三種勝肽+無油配方打造澎潤蘋果肌:首次結合3種勝肽(寡肽-1、十三勝肽-1、六勝肽)和蘋果萃取,打造澎彈蘋果肌。關鍵無油配方,質地輕盈、一抹化水,讓肌膚沒有負擔!90% 感受立即澎彈*
2.保濕、貼妝一次到位:添加角鯊烷和六勝肽,使肌膚達到完美油水平衡,保濕、完美貼妝
3.依據膚況搭配不同抗老精華 完美封存澎彈緊潤:搭配勝肽家族膠原緊緻精萃,快速急救動態紋路,搭配凝霜澎彈效果加倍,搭配A醇精華,全面撫紋、讓肌膚澎彈緊實又保濕
\ *根據30名受試者使用之自我評估結果
《關鍵成分》
•三種勝肽(寡肽-1/十三勝肽-1/六勝肽):增強肌膚屏障,改善臉部及使肌膚保水平衡、緊緻肌膚 。
•角鯊烷:有助於滋潤、修護肌膚,恢復肌膚柔順平滑。
•蘋果萃取:對抗肌膚老化 ,保持肌膚彈性 。
《使用方式》
建議取十元硬幣大小的量塗抹於臉部和頸部,並避免接觸眼睛。日間使用,建議搭配防曬乳。
《購買資訊》官網頁面

PAULA’S CHOICE 寶拉珍選
高效勝肽膠原緊緻霜
全新上市
高效勝肽膠原潤脣精華
(15ml) 售價:NT$980
勝肽配方15分鐘提升嘴脣豐潤度,顯著淡化脣部紋路 ,柔滑質地快速吸收不黏膩,隨時保濕修護,打造柔軟飽滿的嘟嘟脣。
■無人工香料、無酒精、無麩質、無矽靈、無Paraben系列防腐劑、純素
《產品亮點》
1.15分鐘雙脣顯著豐滿提升 打造光澤豐潤脣:勝肽配方提升嘴脣豐潤度,顯著淡化脣部紋路 ,柔滑質地快速吸收不黏膩,隨時保濕修護,打造柔軟飽滿的嘟嘟脣
2.有感推薦:
15分鐘雙脣顯著豐潤提升 *
長效澎潤雙脣*
97% 受試者感受雙脣立即保濕水潤 **
*根據原料供應商針對12位女性受試者使用與本產品相同濃度的十三勝肽-1針對雙脣豐潤之臨牀測試結果
**根據35位受試者連續使用3週的自我評估結果
《關鍵成分》
•十三勝肽-1:顯著減少脣部紋路且可於15分鐘見豐潤效果。
•棕櫚醯三肽-1:對抗脣膚老化
•棕櫚醯三肽-38:幫助脣部密集補水保濕
《使用方式》
隨時需要時以及睡前塗抹,白天使用後請再塗上脣部防曬產品。
《購買資訊》官網頁面

PAULA’S CHOICE 寶拉珍選
高效勝肽膠原潤脣精華

高效勝肽膠原緊緻精萃
(20ml) 售價:NT2,130
寶拉珍選獨家高效勝肽精華-高效勝肽膠原緊緻精萃,特添加十三勝肽-1,研究實證15分鐘即可快速撫平動態紋路*!#15分鐘撫紋精萃 採用全球獨家勝肽科技,為肌膚注入的膠原彈潤因子,幫助穩固肌膚,提升肌膚彈性、緊緻度及強韌度。
《產品亮點》
1.震撼市場! 15分鐘快速撫平動態紋路*:添加十三勝肽-1,內含13種胺基酸,能減少臉部動態紋路的產生,可在15分鐘內快速撫平動態紋路*
2.全球獨家勝肽科技!提升肌膚彈性和緊緻度:全球獨家勝肽科技,能深入肌底緊緻肌膚,並結合獨家多勝肽-121及四勝肽-72,加速肌膚修護,回復肌膚彈性,再添加獨家勝肽配方,減緩肌膚老化疲態,讓肌膚更加澎潤、緊實有彈性
3.客製化打造更加緊緻的臉部輪廓:可單獨使用或搭配A醇精華液,快速撫平臉部動態紋路,同時修護混和保養、雙層抗老,緊緻和撫紋效果加乘
*來自原料供應商針對35位女性受試者使用與本產品相同濃度的十三勝肽-1之臨牀測試結果。
《關鍵成分》
•十三勝肽-1 -減少臉部動態紋路的產生*
•多勝肽-121 -增加肌膚彈性和緊實度
•四勝肽-72 -支撐肌膚的屏障,提升肌膚彈力
《使用方式》
請於清潔、化妝水與去角質後,取適量塗抹於臉部及頸部肌膚,此勝肽精華可單獨使用或混合任一精華或保濕產品使用,請避免接觸眼睛及嘴脣。建議依肌膚需求,搭配後續保濕產品,白天建議搭配使用 SPF30 以上防曬乳。
《購買資訊》官網頁面

PAULA’S CHOICE 寶拉珍選
高效勝肽膠原緊緻精萃
標題:【PAULA’S CHOICE 寶拉珍選】寶拉珍選 全新上市勝肽新品! 高效勝肽膠原緊緻霜、高效勝肽膠原潤脣精華 打造澎潤臉頰、豐滿雙脣 全臉粉嫩澎彈超減齡 /
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。


