記者陳芊秀/綜合報導
女星玥熹(原藝名夏乙薇)以其活潑開朗的個性,經常出現在各大綜藝節目中,深受觀眾喜愛。而她昨日(12)發長文透露自己罹患中度「微笑型憂鬱症」,並伴隨口喫症狀、自律神經失調等問題。她寫下自身經歷,鼓勵其他同樣受到此疾病困擾的人:「我們都可以慢慢變得更好!」

玥熹坦言,自己正面對中度「微笑型憂鬱症」及嚴重的自律神經失調。儘管身心健康受到了挑戰,但她依然充滿正能量地表示:「這些都無法阻礙我前進的腳步。夢想與目標始終在我心中閃耀,我會勇敢追尋屬於自己的樂園。」她回憶起去年父親突然離世後,接連經歷葬儀社一連串離譜事件,她幾乎未曾給自己片刻喘息。她寫道:「我要處理父親的後事,還要處理因葬儀社偷拍而上新聞的事,當時開了記者會,還要打官司,又要工作。什麼都自己一個人來。」這些壓力讓身心負擔越來越沉重。
直到某天,玥熹察覺自己開始出現口喫和結巴的症狀,才意識到情況的嚴重性,就醫後得知罹患中度憂鬱症,屬於「微笑型憂鬱症」患者。她說:「我一直都有猜想,我可能患有一點憂鬱症之類的,只是沒想到我有這麼誇張,甚至到中度,還自律神經失調。」

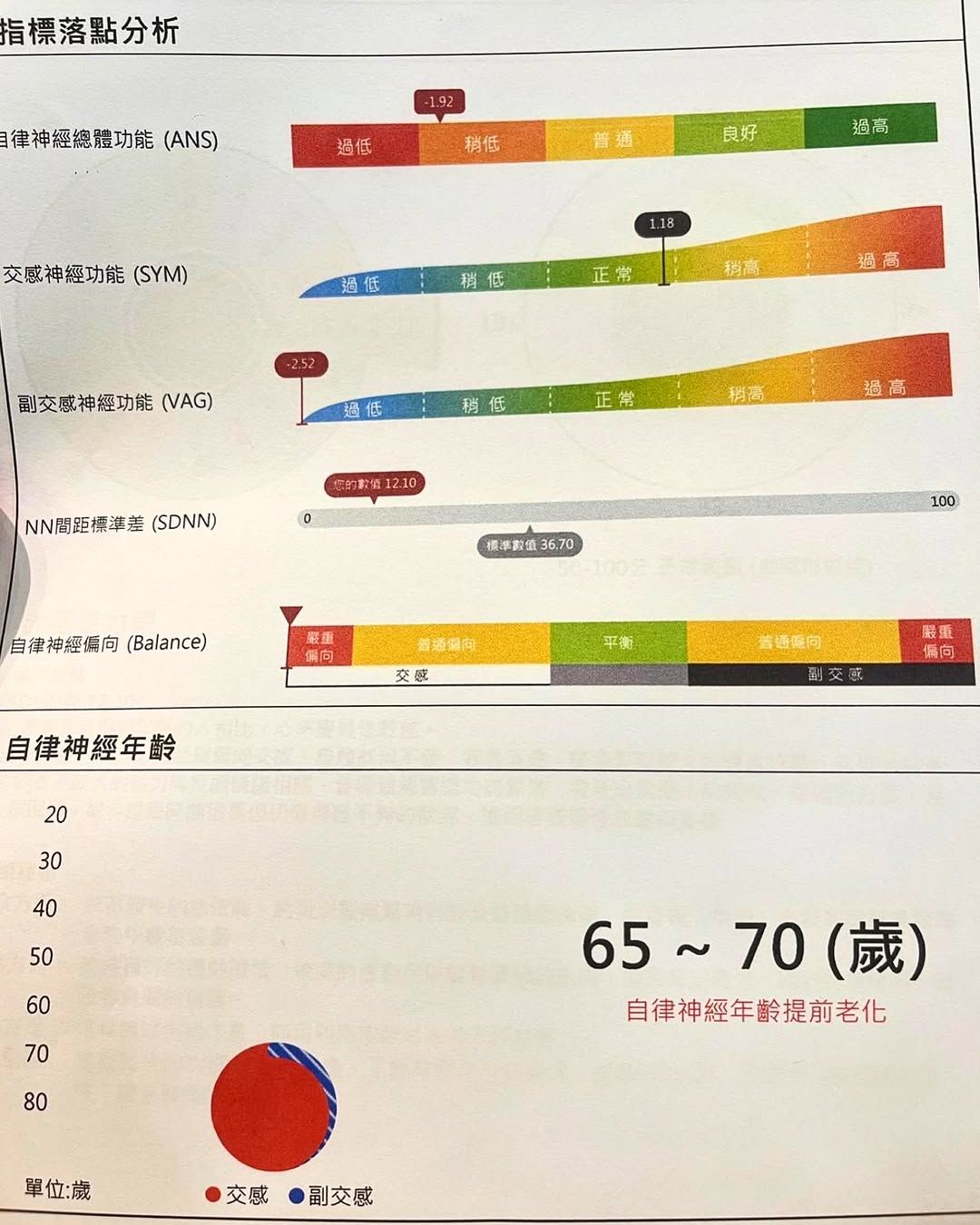
或許因為經歷了生離死別,玥熹被逼迫快速成長,看待生死變得坦然,選擇默默承受所有的痛苦,「因為這樣,我一直希望帶給這世界更多的愛與溫暖,也希望這世界能有更多的善與愛。」同時,她也引用一段話,「善良,是一種選擇,但也要懂得保護自己。別因為自己的善良,成為了讓人好欺負的對象」。她長文附上照片,透露自己自律神經年齡落在65至70歲,文末不忘感謝一路上幫助自己的人。
標題:女星突口喫、自律神經失調急就醫!玥熹驚罹「中度微笑型憂鬱症」
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。