記者黃庠棻/台北報導
《破·地獄》榮登香港影史最賣座華語片榜首,目前票房突破1億3500萬港幣(約5.5億台幣),除了持續拉開同樣由黃子華主演的《毒舌大狀》票房差距,更突破200萬人次進戲院的觀影記錄,台灣好評持續發酵,票房穩定成長,全台票房突破865萬台幣,也掀起台灣殯葬業從業人員的觀看潮。
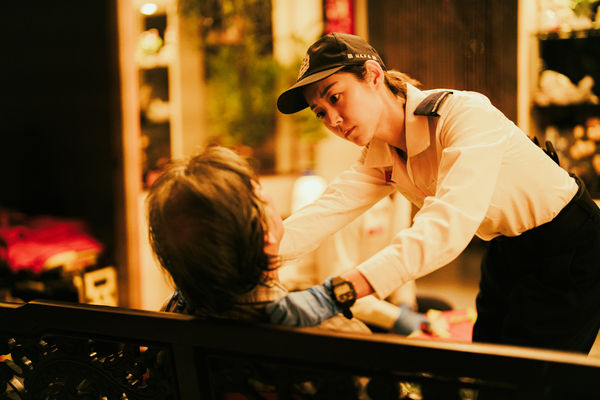
許冠文對票房成績開心到講不出話來,上映前他曾打賭預估票房接近1億2000萬港幣,現在更可以毫無疑問告訴自己「知道觀眾喜歡什麼」。《破.地獄》無疑也已經成為他的代表作,他透露曾是「香港歌神」的弟弟許冠傑看完《破.地獄》後,對林家謙包辦作詞作曲編曲及主唱的主題曲讚譽有加,歌詞令人驚歎,比他更厲害。導演陳茂賢也表示〈普渡眾生〉這首歌讓電影更完整、更圓滿,呼籲影迷要把歌聽完,據瞭林家謙也將於這個月來台發片。

影迷敲碗許久的影人謝票場,終於確定導演陳茂賢協同女主角衛詩雅來台謝票,很久沒來台灣的兩個人同聲說道「超想念台灣!很想趕快跟大家見面!」兩個人會出席19日以及20日的影人QA場次,與影迷近距離面對面,觀眾紛紛在社群上留言「終於要來了嗎?真的太期待了」﹑「真的太興奮了!一定要去給我們的導演跟文玥加油支持!!」

《破·地獄》從各個面向勾起各地華人觀眾的深刻共鳴,除了香港以外,票房旋風在馬來西亞、英國、澳洲各地全部都造成轟動且創下佳績。台灣觀眾的好評也在社群上持續延燒。電影雖然討論死亡議題,但其實更多的是對生命的理解和尊重,讓各地觀眾都在欣賞電影的同時擁有更多共鳴與感動。

與香港有特殊感情的女星曾寶儀看完電影,提到「好喜歡裡面兄妹及父女的對話,要足夠地真誠,才能看見地獄的虛妄。我特別想說說演哥哥的朱栢康,《金都》的時候我就好喜歡他,好生活、好香港。不會覺得他在演,他就是那個讓整件事變真的人,《破地獄》的他也是。兄妹二人在醫院走廊攤牌的那場戲,真誠到不忍苛責那個原本會視為不討喜的角色,那對我來說是一個演員很高的境界。」
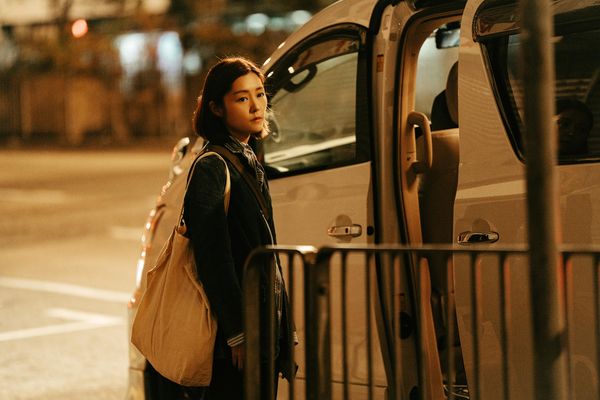
電影《破·地獄》好評不斷,影評們也都紛紛分享自己的推薦,影評「香功堂主」分享「《破·地獄》無意全盤否定傳統的價值,它終究透過『南音』的傳唱來告訴觀眾,生活的平衡,不能只看亡者,也要照看生者。」而影評「半瓶醋」則分享「當電影中的角色們碰到我們在現實生活中的類似經驗,會讓觀眾出戲院之後會更想要珍惜自己的生活與家人,《破。地獄》就是這樣一部有著反映當代觀眾們的痛苦,並在片中給出化解情感的電影。」
電影《破·地獄》講述新冠疫情後百業蕭條,婚禮顧問魏道生(黃子華飾)被迫轉行改做殯儀禮儀,由於紅白二事大相逕庭,道生處處碰壁,並與專做道教超度儀式的事業夥伴「喃嘸師傅」文哥(許冠文飾)產生許多衝突,幸有文哥女兒文玥(衛詩雅飾)居中化解,也逐漸悟到殯葬服務的真義,需要被超度的不只亡者、在生者更需要被超度,即「破地獄」的真諦。
標題:票房破5.5億「登香港影史最賣座」 《破·地獄》導演確定來台!
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。