
電動車市場需求正盛,今年累計至12月22日,純電動車領牌台數為36,627輛,較去年同期成長48%,成長主要來自納智捷與豪華車品牌。雙B與保時捷持續加碼電動車款,隨著更多車款加入市場,預期明年整體電動車成長幅度可能趨緩,但豪華車品牌的電動車將持續成長。
相較於以往電動車逐年銷量倍增的大幅成長,業者認為,未來電動車成長將會趨緩,除基礎設施的限制、電動車里程焦慮的問題,先前購車意願強烈的消費者已陸續領車,BMW總代理汎德汽車(2247)認為,今年電動車占BMW 7整體掛牌數三成,明年也約三成左右,但BMW預期明年整體銷售持續成長,因此電動車銷售也將增加。
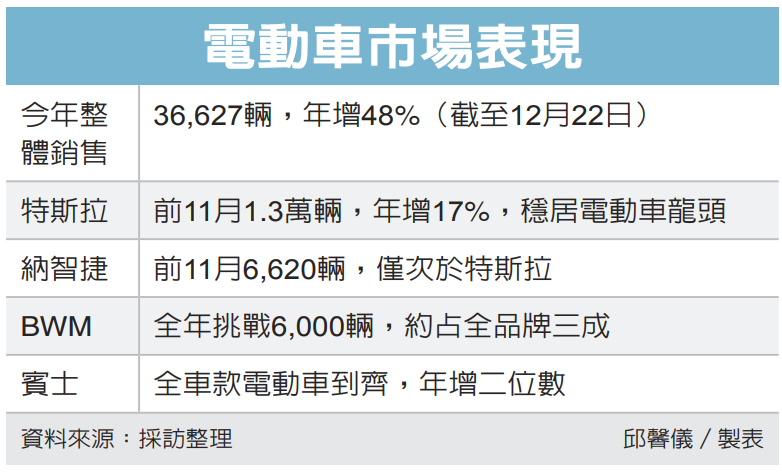
保時捷今年全年在台銷量可望再創新高,全年在台領掛牌數接近6,000輛,保時捷在台電動車不含全新純電Macan,電動車占保時捷在台灣整體銷售比例略高過一成、約600輛左右。Macan EV為近期保時捷發表的首款純電SUV,目前接單已破800張,交車時間將會落在明年,因此初估保時捷明年新車陸續抵台,不只推升整體銷售量,電動車的領掛牌數更會大幅成長。
今年台灣電動車的主力來源是特斯拉與納智捷,特斯拉今年前11月領掛牌數達1.3萬輛,較去年同期成長17%;納智捷的n7累積掛牌數為6,620輛,相對於去年全年幾乎是淨增加,也形成台灣電動車占整體車市約9%的重要基礎。
除特斯拉與納智捷以外,主要的電動車供應來源仍以豪華車品牌為主,保時捷電動車穩定供應,台灣賓士指出,今年電動車在台掛牌數會較去年有二位數成長。
今年BMW前11月掛牌數達1.87萬輛,預期全年將突破2萬輛,創下歷年新高,其中電動車占比約達三成,數量相當可觀。BMW也是電動車掛牌數僅次於特斯拉的豪華車品牌。
BMW總代理汎德汽車指出,對於明年台灣新車整體市場成長性抱持期待,iX1與iX2仍有待交訂單待消化,再加上X3大改款,明年還將加入iX3,成為電動車的主力車款,預期將是明年電動車銷售成長的主力。
原文轉載來自:來源連結