記者潘慧中/綜合報導
近期詐騙事件頻傳,還一路延燒到演藝圈,繼譚艾珍、郭彥均證實被騙,男星嘻小瓜12日也在社群網站坦承遭詐騙,事件發生在2024年10月中旬。

嘻小瓜解釋朋友當時聲稱有搶到2NE1的門票後,詢問他是否要一起看,他隨即答應並匯款給友人,「中間都一直認為有票。」然而,直到12月中旬,朋友詢問賣家取票事宜時,竟發現賣家已退出LINE且無回應。
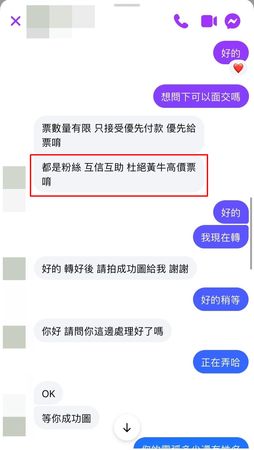
朋友這才坦承門票是從網路社團購買,並非透過官方搶票,「她不覺得是詐騙是因為賣家7800的票只加200賣我們8000,說粉絲互助,互相幫忙,還說杜絕黃牛!!」嘻小瓜無奈說道。
更誇張的是,嘻小瓜後來還發現賣家以同一張票圖騙了四個人,讓他非常生氣,「為什麼要騙粉絲的錢!!粉絲想支持偶像,到底為什麼要騙這個!!我們出社會的大人,被騙錢當然可以當作花錢消災,但很多都是小朋友,他們花多少時間存錢,只是想見偶像一面!!」

嘻小瓜坦言錢已無法追回,並感嘆詐騙行為難以有效制止,就算報警也僅停用人頭帳號,無法對詐騙集團施加刑責。他只能提醒大家要更加小心謹慎,「詐騙手法層出不窮,希望藉由我的經驗讓大家也可以警惕!」
對….我被詐騙了!!
去年十月中我朋友問我要不要去看演唱會,她說她搶到票,我就說有票當然可以呀,我就匯款給朋友,中間都一直認為有票
直到12月中朋友突然想問賣家,什麼時候可以取票,發現那個賣場已經退出LINE,我朋友密她臉書也不回,她才驚覺可能被詐騙
這時候她才坦承跟我說她不是官方搶到票,是網路社團購買,因為她不覺得是詐騙是因為賣家7800的票只加200賣我們8000,說粉絲互助,互相幫忙,還說杜絕黃牛!!
她跟我講我我才知道這些內容,這時候我只能解決問題!
我之前說被詐騙的就是這件事情,之前一直不敢確認是否被詐騙,是因為取票時間還沒有到,然後也覺得再等一下好了的心態!
直到我前天發文,找到一模一樣座位的粉絲,同一張圖賣給四個人,才正式確認「被詐騙」了,我覺得很生氣的點事,為什麼要騙粉絲的錢!!
粉絲想支持偶像,到底為什麼要騙這個!!我們出社會的大人,被騙錢當然可以當作花錢消災,但很多都是小朋友,他們花多少時間存錢,只是想見偶像一面!!
你們這些詐騙集團的人,騙人家小朋友的錢,然後去旅行、過爽日子,到底幹嘛不正正當當去工作,我真的非常生氣欸!!
目前當然知道錢是拿不回來,但為什麼詐騙都可以逍遙法外,都不會有刑責,就算報警處理,也只是停用人頭帳號罷了!到底為什麼沒有可以解決的方法呢?
希望大家可以再小心謹慎!詐騙手法層出不窮,希望藉由我的經驗讓大家也可以警惕!
#詐騙 #新聞 #2ne1 #演唱會 #concert
標題:台男星遭詐騙+1!買2NE1門票「匯款完賣家消失」 嘻小瓜怒揭話術
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。

