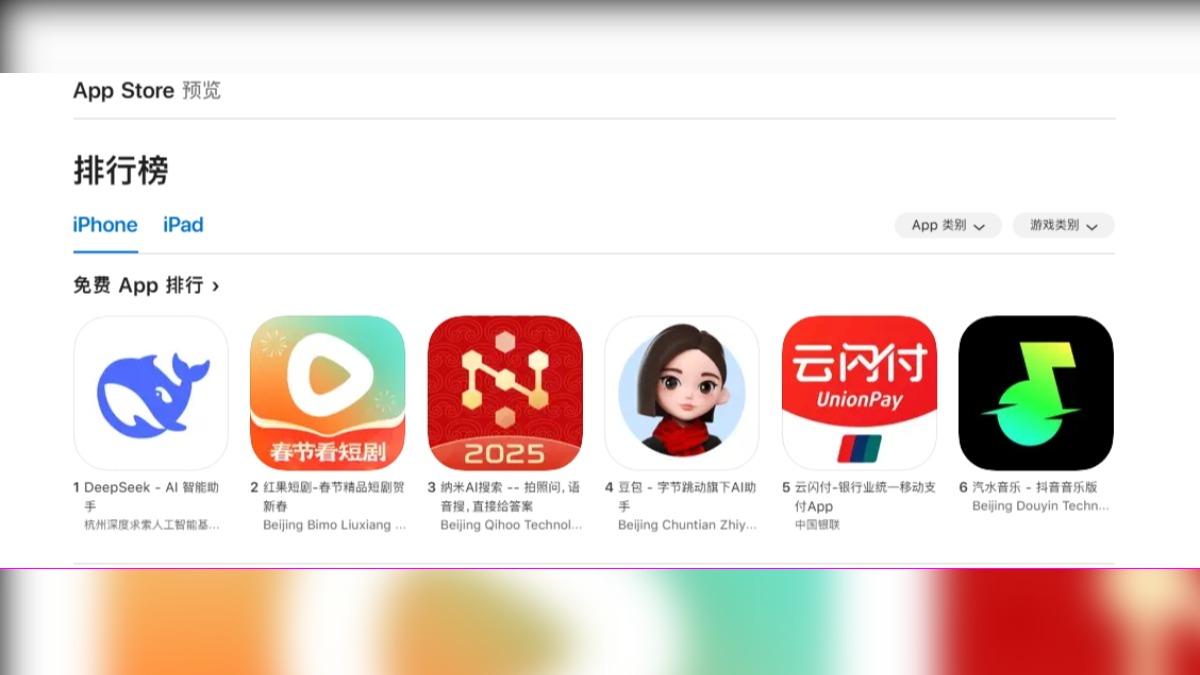
近日,AI新創公司 DeepSeek成為科技界的熱門話題,憑藉其最新推出的開源大型語言模型(LLM)「DeepSeek-V3」與「DeepSeek-R1」,甚至引發了矽谷的恐慌。DeepSeek-V3 在測試中超越了Meta的 Llama 3.1 並展示出卓越的訓練效率,且其成本也大幅低於同類競爭對手。另外DeepSeek在手機應用排行榜上也有好表現,蘋果ios的中國和美國商店的免費下載排行榜上都霸榜第一。

DeepSeek利用僅2048張H800 GPU並經過兩個月的訓練,成功推出了擁有6710億參數的模型;相比Meta花費超過1.6萬張H100 GPU和數億美元訓練時間,才能完成 4050億參數的Llama 3.1,震驚業界。根據CNBC報導,DeepSeek的成功不僅限於其模型的表現,還包括其巧妙躲避美國晶片禁令的策略。雖然美國自2022年起對中國的高性能 AI 晶片如輝達的 H100 和 H200 設立出口管制,DeepSeek卻仍然能夠獲得大規模的輝達晶片支持。
知名AI新創公司Scale AI的創辦人 Alexandr Wang揭露,DeepSeek擁有多達5萬張被禁銷的輝達 H100 晶片,這一消息引發了對中國AI產業突破美國出口禁令的討論。Wang強調,儘管這些資訊無法公開討論,但DeepSeek顯然找到了途徑,突破了美國政府的出口管制。DeepSeek的創始人梁文鋒,原本是量化對沖基金幻方量化 High-Flyer 的創辦人,憑藉這一背景,他成功將 DeepSeek 打造成為一個無需依賴外部投資者的高效新創公司。DeepSeek的成就背後,除了創新模型架構外,還有混合專家架構(MoE)和多頭潛在注意力(MLA)等先進技術的加持。這些技術顯著提高了運算效率,並且 DeepSeek 還運用知識蒸餾技術將大型模型的能力有效轉移至更小型的高效模型中,讓其運行成本進一步降低。對於DeepSeek在全球市場的擴展,矽谷的反應不一。Meta的一名工程師透露,DeepSeek的崛起已經引發了公司內部的恐慌,特別是在其模型表現上超越了 Llama 3.1。為應對威脅,Meta甚至設立了四個專案部門,專門研究DeepSeek的技術。
標題:陸AIDeepSeek疑擁輝達晶片 美中免費App下載排第一、Meta怕怕
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。