
2024年以來累計賣超台股逾6,700億元,但對指標型金控買多於賣,包括金控雙雄富邦金(2881)、(2882),以及凱基金(2883)、元大金(2885)等今年來獲利高成長個股,專家預期,近來金融併購話題再起有利評價,以及面對「川普2.0」金融業相對較不受衝擊,外資買超顯示對其前景看好。
金融業操盤人分析,今年來先有台新、新光的金金併炒熱市場,日前又有永豐金併購京城銀,以後者股價淨值比1.1倍成交,對有意出售的金融機構,或是因競爭排名改變而增加併購意願的金控,可望產生激勵作用。金控2024年獲利可望刷新紀錄,有利明年股利配發,有利金融行情。
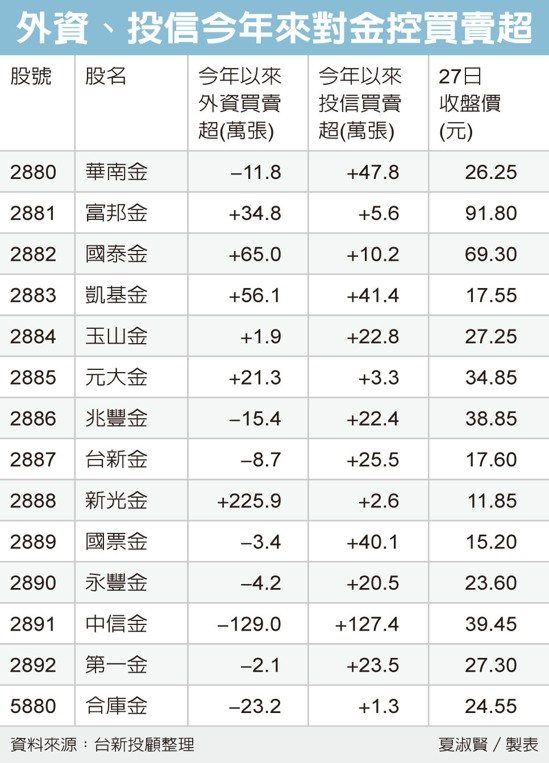
外資今年買超幾檔指標大型金控股,除具有被併題材的新光金,外資今年累計大買225.9萬張外,大買國泰金65萬張,以國泰金年線約在57.7元附近概算,約砸了375億元買國泰金。
其次買超凱基金達56萬張,買超富邦金約34.8萬張。以富邦金股價概估,外資買超金額也有近280億元,相當於外資今年來對金控雙雄合計大買超過600億元,對照其賣超台股,外資對金控雙雄的青睞不言可喻。
台新投顧副總經理黃文清指出,今年來外資大賣台股,凸顯在美國降息下,外資資金回流台股力道不如預期,對台股包括科技股、各產業大型權值股著墨力道均不顯著,甚至站在賣方。
相較之下,金融族群具有基本面成長性、相對低位階、明年股息殖利率等題材,今年再起的金融併購熱潮,對金融股評價與投資信心有正面幫助,應是外資買超關鍵。
投信發行台股ETF 2024年大爆發,尤其高股息概念ETF更是推升金控股股價主力,統計2024年以來投信法人對金控股呈現全面買超,預期高息ETF對金控股布局可望持續。
2024年來投信最愛首推中信金,累計買超達127.5萬張,投信買超超過40萬張的金控股,還有華南金、凱基金、國票金;對玉山金、兆豐金、台新金、永豐金、第一金等都逾20萬張。
標題:金融併購熱炒外資追捧 今年來敲進富邦、國泰等
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。