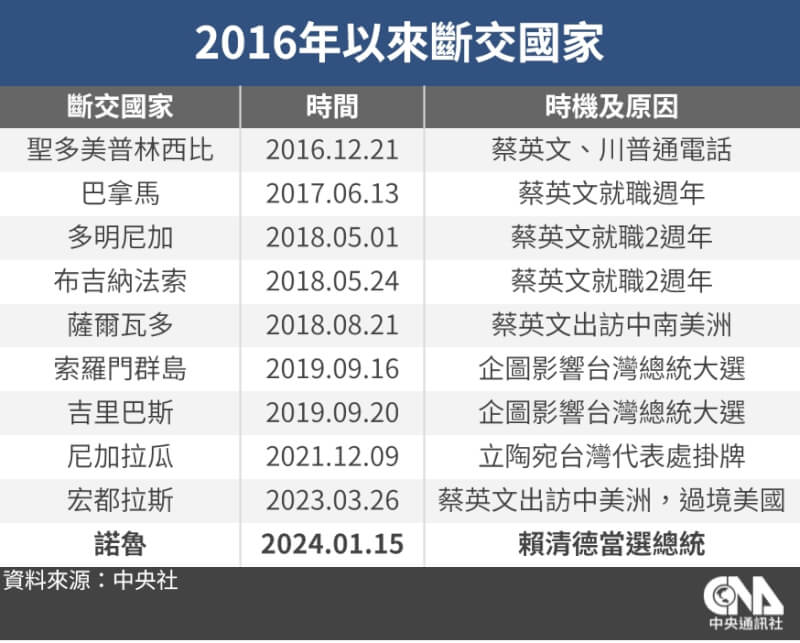
台灣與諾魯斷交 外交部:諾國比價中國索求鉅額經援
外交部15日召開記者會聲明,台灣獲悉諾魯將以聯合國2758號決議及一中原則等理由與中華民國斷交,為維護國家尊嚴與主權,終止與諾魯外交關係。外交部政務次長田中光指出,去年即已掌握中國積極接觸諾魯政要,利用經濟援助誘使該國外交轉向等情資。諾魯向台灣索求鉅額經濟援助,其中難民中心1年,佔諾魯每年預算總額逾二分之一。,北京當局在全球祝福台灣順利完成大選之時進行外交打壓,公然挑戰國際穩定秩序。()
中國奪台灣友邦8年出手10次 學者:選後施壓賴清德測試底線
台灣與諾魯斷交後邦交國降至12國,自總統蔡英文2016年5月20日就任以來,包含諾魯在內已有因中方介入打壓而與台灣終止外交關係。對於台灣大選甫落幕,諾魯就無預警與台斷交並與中國復交,學者分析,這次總統選舉將台灣拉高到國際議題,中國一定要有所動作,一方面是施壓台灣及總統當選人賴清德,另一方面也是做給美國看,針對民進黨及未來新政府的施壓計畫早有布局,從現在到5月20日的這段時間非常關鍵。()
蔡總統:美代表團來訪意義重大 凸顯台美緊密關係
蔡總統15日接見美國跨黨派資深代表團時表示,台灣剛完成總統及立委大選,美方立即發表祝賀聲明,並派遣重量級跨黨派代表團訪問台灣,意義重大,不僅充分展現美國對台灣民主的支持,更凸顯台美緊密堅實的夥伴關係。來訪的美國前國家安全顧問哈德利說,期待台灣新政府上任延續台美關係,共同維護台海兩岸和平穩定;前副國務卿史坦伯格則表示,美方重視以和平方式解決兩岸爭端,反對任何單方面改變現狀行為。()
李進勇駁斥作票傳言:有舞弊就辭職 造謠者送檢調
總統與立委選舉13日投開票完畢,網路流傳影片指部分投開票所出現灌票、「喊柯文哲,劃票都沒劃1號」、紙製票匭底部有夾層藏票等情形。中選會主委李進勇15日表示,非常遺憾少數人散播錯假訊息,攻擊選務機關、污衊24萬名以上選務人員,讓他非常痛心,若候選人陣營不能接受選舉結果請依法提起訴訟,只要法院認定有違法舞弊、作票情形存在,他立刻辭職。()
經部:去年台廠赴中投資跌破千億元大關 創21年新低
經濟部15日表示,去年全年僑外投資額逾112億美元,年減15.40%,但仍創近16年來第3高;對中國大陸投資額則約30億美元,創21年來新低、年減近4成,且連續第2年低於對新南向國家投資,顯示台商順應國際供應鏈重組,調整全球布局以分散風險。()
施明德83歲辭世 坐政治黑牢逾25年獲譽台灣曼德拉
前民進黨主席施明德15日辭世,他無畏威權統治下與之對抗,是台灣從黨外運動到民主化歷程最具指標性人物,一生兩度以叛亂罪被判處無期徒刑,坐牢時間超過25年,被譽為台灣曼德拉。他的女兒施笳、施蜜娜透過臉書表示,父親在生日這天啟程,與等待他的家人和一同出生入死的戰友們團聚,「不管是在此岸或是彼岸,他都不曾孤單」。蔡總統得知訊息哀傷不捨盼家屬節哀珍重,民進黨也表達沉痛哀悼。前總統形容施明德是一代梟雄、民主先知,並回顧倒扁運動隔年,施明德孤單在看台看國慶表演的昔日往事。()
立院龍頭與誰合作 民眾黨要求藍綠提國會改革主張
立委選舉結果三黨不過半,外界關注2月1日開議後的立法院正副院長選舉,是否可能藍白合作或綠白合作。黃珊珊、黃國昌等8位民眾黨不分區立委當選人15日提出新國會改革訴求,包含修法建立國會聽證調查制度、強化人事同意權審查等規範,並要求有意競逐立法院正副院長人選具體回應民眾黨訴求,屆時將作為黨團投票的態度依據。對於外界關注是否可能自提正副院長,國會改革更重要,未來將團進團出投票。()
以哈戰爭百日人質命運未卜 特拉維夫24小時集會聲援
以哈戰爭爆發至15日屆滿100天,被哈瑪斯劫持人質家屬及志願組織13日晚間在特拉維夫舉行24小時「百日集會」,呼籲政府解救親人回家,以色列總統赫佐格、美國駐以大使也出席聲援。雖然近期將藥物轉交給人質的協議已有進展,但以色列民眾對政府策略看法仍分歧,一些家屬堅持應該更積極尋求政治解決方案,而非軍事手段。據以色列官方統計,目前仍有超過130人遭囚至加薩,據信至少25人被殺身亡。()
強烈大陸冷氣團21日報到 台北低溫下探11度
中央氣象署預報,16日持續受東北季風影響,大台北山區、東半部仍有短暫雨;預估21日起強烈大陸冷氣團影響,可能持續至24日,全台降溫,台北低溫約11、12度,各地局部沿海空曠地區或近山區平地可能更低。22日晚間起若水氣及溫度能配合,合歡山等3000公尺以上的高山有機會降雪。()
Novavax XBB疫苗供貨不及 台北榮總馬偕長庚等醫院暫停預約
近期國內外COVID-19疫情升溫,XBB疫苗接種人次12日達3萬4883人次,創9月底開打以來單日新高;其中莫德納XBB疫苗當日接種2萬4236人次為開打以來次高,Novavax XBB當日接種1萬674人次為開打以來最高。由於已到貨Novavax疫苗其中16.5萬劑不合格,另16.47萬劑尚待檢驗審查致供貨不及,北市各醫學中心陸續暫停預約接種,疾管署建議民眾可優先選擇莫德納接種。()
開箱老照片》許炳棠發起成立國華廣告
國華廣告有「台灣廣告大學」美譽,曾培育多位廣告人才。創辦人許炳棠1960年赴日參加第2屆亞洲廣告會議,種下創立廣告代理業契機,隔年1月發起和日本電通公司合作的台灣廣告事業股份有限公司,「國華廣告公司」同年5月正式成立。之後除了與聯合報、中央日報簽訂台灣第一個廣告代理制度合約,還與台北市府訂下還在興建的中華商場屋頂廣告承攬權,將之改裝為廣告霓虹燈箱,讓廣告業在台灣站穩腳步。()
以下平台上午8時同時發布早安世界,給你最精華的新聞摘要!
、、、
標題:早安世界》台灣與諾魯斷交 外交部:諾國比價中國索求鉅額經援
鄭重聲明:本文版權歸原作者所有,轉載文章僅爲傳播更多信息之目的,如有侵權行爲,請第一時間聯系我們修改或刪除,多謝。









