記者項瀚/台北報導
東湖36年平價日料熱炒「三戶料亭」將歇業,老員工說:「老闆快70歲,二代不接手,而且我們所有員工也都是年輕做到老,筋骨、身體都壞掉了,該退休了,歇業與店租、生意量無關。」房仲表示,該店位於康樂街,店面效益不差。

▲東湖36年平價日料熱炒「三戶料亭」將歇業。(圖/記者項瀚攝)
在東湖開業36年的「三戶料亭」,有日式料理、各式熱炒等餐點,生意相當不錯,在當地也頗有名。不過,近期該店傳只營業到12月22日,公告上寫著「我們要退休了,感謝大家36年來的支持愛護和照顧。」讓許多老顧客相當不捨。
記者平日下午走訪,人潮還是不少。一位老員工表示:「老闆快70歲,年紀大了,二代不接手,而且我們所有員工也都是年輕做到老,筋骨、身體都壞掉了,該退休了。」
她說:「歇業原因主要就是大家都老了,與生意、店租無關,我們生意量一直都ok,店租每月5~6萬元內可以搞定,也不是問題。」
經查謄本,「三戶料亭」店面在2017年曾換過房東,在地人林姓自然人以買賣取得。再看實價登錄,該店面含1車位權狀23.8,當時以總價2050萬元,平均單價約86萬元左右。
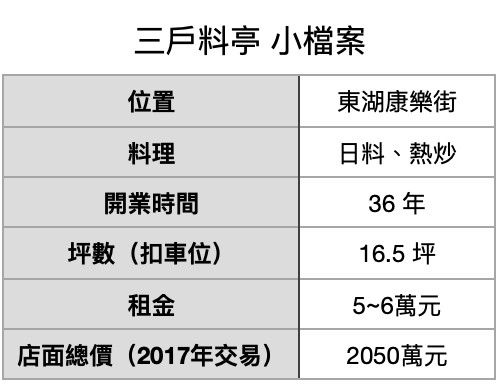
▲「三戶料亭」小檔案整理。(表/記者項瀚製)
信義房屋不動產企研室專案經理曾敬德表示,東湖住宅人口多,又有不少所學校,因此商圈熱鬧,店面效益都相當不錯,最熱鬧的是東湖路商圈,沿線幾乎沒有空店面,去年連鎖速食業者還以年租348萬元進駐該區。
曾敬德接著表示,「三戶料亭」位於康樂街,與東湖商圈相距不遠,也算是東湖熱鬧的區域,沿線空店面也不多,但路寬比較窄,人潮還是比東湖路少,觀察該區零售型業種會少一些,主要以平價餐飲為主。

▲東湖地區最熱鬧的是東湖路商圈。(圖/記者項瀚攝)
標題:東湖36年美食老店將歇業 員工:大家年輕做到老「身體都壞了」
聲明: 本文版權屬原作者。轉載內容僅供資訊傳遞,不涉及任何投資建議。如有侵權,請立即告知,我們將儘速處理。感謝您的理解。


